Pass Your Microsoft Certified: Azure Data Scientist Associate Certification Easy!
Microsoft Certified: Azure Data Scientist Associate Certification Exams Questions & Answers, Accurate & Verified By IT Experts
Instant Download, Free Fast Updates, 99.6% Pass Rate.

Designing and Implementing a Data Science Solution on Azure
Includes 432 Questions & Answers
$69.99
Microsoft Certified: Azure Data Scientist Associate Certification Exams Screenshots
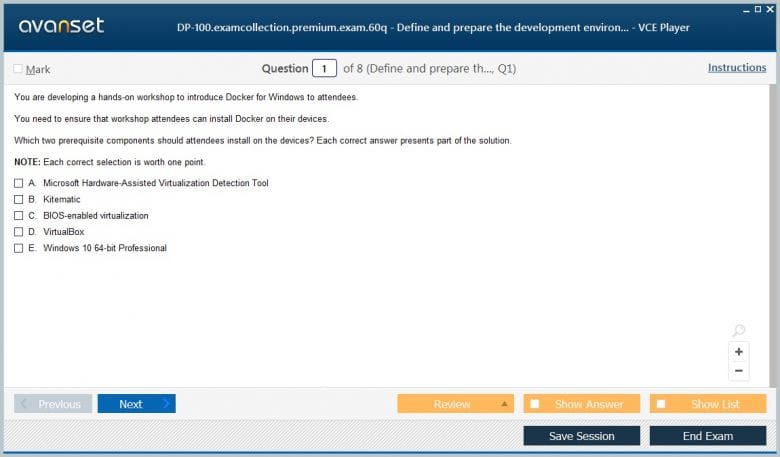
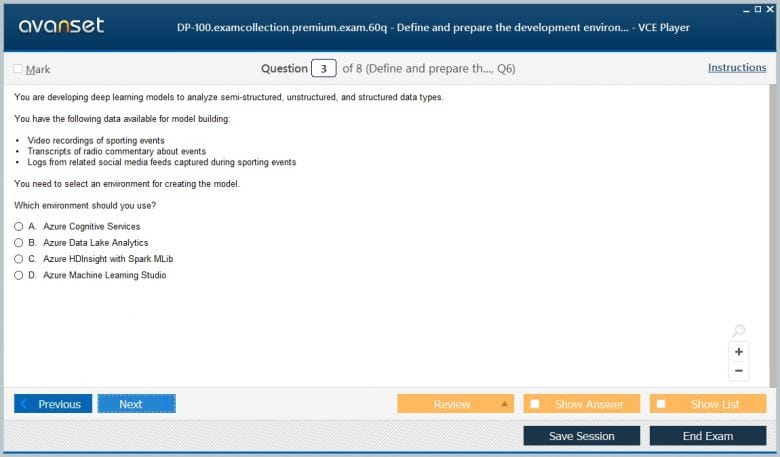
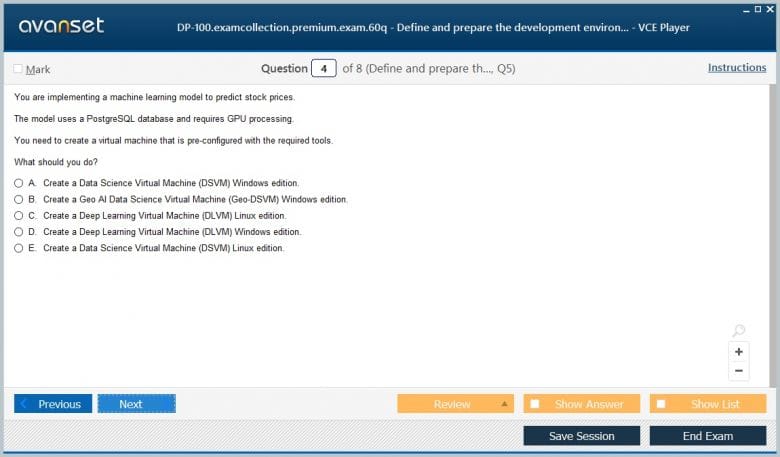
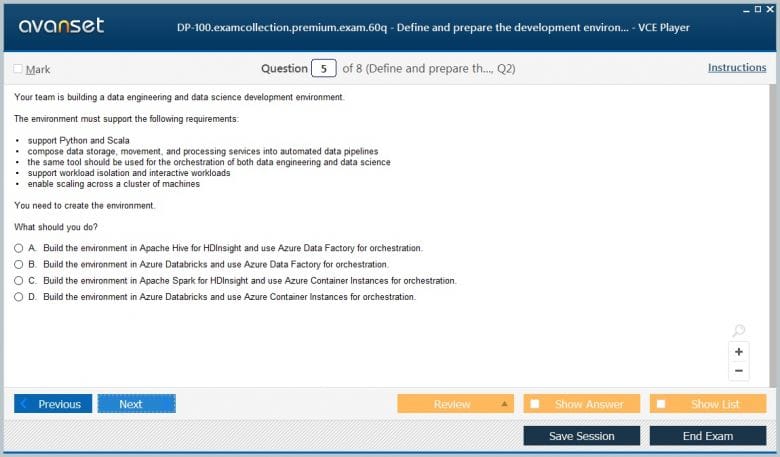
Microsoft Certified: Azure Data Scientist Associate Product Reviews
Download Free Microsoft Certified: Azure Data Scientist Associate Practice Test Questions VCE Files
| Exam | Title | Files |
|---|---|---|
Exam DP-100 |
Title Designing and Implementing a Data Science Solution on Azure |
Files 10 |
Microsoft Certified: Azure Data Scientist Associate Certification Exam Dumps & Practice Test Questions
Prepare with top-notch Microsoft Certified: Azure Data Scientist Associate certification practice test questions and answers, vce exam dumps, study guide, video training course from ExamCollection. All Microsoft Certified: Azure Data Scientist Associate certification exam dumps & practice test questions and answers are uploaded by users who have passed the exam themselves and formatted them into vce file format.
The Ultimate Guide to Becoming a Microsoft Azure Data Scientist Associate
The modern world runs on data. Every interaction, transaction, and process generates information that businesses can use to improve performance and create value. Organizations across all industries, from healthcare to retail to finance, are realizing that their competitive advantage lies in how effectively they can harness data. At the center of this transformation are data scientists, professionals capable of turning raw numbers into actionable strategies.
The cloud has become the natural home for data-driven solutions. With its ability to store vast amounts of data, provide scalable compute resources, and offer advanced machine learning tools, the cloud accelerates innovation. Microsoft Azure is one of the leading cloud platforms enabling this evolution. It offers powerful services that make building, deploying, and managing artificial intelligence solutions accessible and efficient. The Microsoft Certified Azure Data Scientist Associate certification was created to validate and enhance the skills of professionals working at this intersection of data science and cloud computing.
Understanding the role of an Azure data scientist
An Azure data scientist is not just someone who analyzes data; they are responsible for transforming raw information into predictive models that can guide decision-making. They combine statistical knowledge, programming skills, and domain expertise with hands-on experience in Azure tools. Their role is both technical and strategic, bridging the gap between business requirements and technical execution.
Typical responsibilities include preparing data for machine learning, selecting algorithms suited for specific tasks, building models, and deploying them into production environments. Beyond these technical aspects, an Azure data scientist must also collaborate with stakeholders, interpret results in business terms, and ensure that models are fair, ethical, and compliant with relevant standards. This blend of technical depth and strategic vision makes the role crucial in today’s organizations.
Key skills required for success
The certification focuses on validating practical and theoretical skills that a modern data scientist needs. Some of the core competencies include:
Designing and creating Azure Machine Learning workspaces and compute resources
Cleaning, transforming, and visualizing datasets
Selecting appropriate algorithms for classification, regression, clustering, or recommendation tasks
Performing feature engineering to improve model performance
Training and evaluating models using key performance metrics
Deploying models as web services and integrating them into business applications
Monitoring model performance and implementing retraining strategies
Applying responsible AI principles to ensure ethical outcomes
These skills go beyond classroom knowledge. They require practical application, often tested in hands-on labs or real-world projects. Proficiency in programming languages like Python is particularly important since many Azure Machine Learning tools integrate directly with Jupyter notebooks and Python libraries.
Exam overview
The certification is achieved by passing the DP-100 exam, officially titled Designing and Implementing a Data Science Solution on Azure. This exam is designed to test a candidate’s ability to perform real-world data science tasks using Azure services.
The exam objectives can be grouped into several major areas:
Setting up Azure Machine Learning workspaces, environments, and compute resources
Preparing data for machine learning, including cleaning, normalization, and feature extraction
Modeling tasks, such as selecting algorithms, training models, and hyperparameter tuning
Deployment, which involves creating inference pipelines and deploying models as web services
Monitoring and retraining models in production to maintain accuracy and reliability
Because the exam covers the full lifecycle of a machine learning project, candidates are expected to understand the end-to-end process rather than isolated tasks. This holistic perspective ensures that certified professionals can deliver complete solutions in real-world environments.
The importance of Azure Machine Learning
At the heart of the certification lies Azure Machine Learning, a cloud platform designed to manage the lifecycle of machine learning projects. It provides tools for data preparation, model training, deployment, and monitoring, all within a scalable environment.
Key features include automated machine learning, which helps identify the best algorithm and parameters for a dataset, and a visual design interface for those who prefer drag-and-drop workflows. Azure Machine Learning also integrates with open-source frameworks such as TensorFlow, PyTorch, and Scikit-learn, giving data scientists flexibility in their approach.
The platform simplifies complex tasks. For example, instead of spending weeks configuring infrastructure, a data scientist can quickly spin up compute clusters, connect to data sources, and begin experimenting. This efficiency is one of the main reasons organizations are adopting Azure for their AI and machine learning needs.
Benefits of earning the certification
Earning the Microsoft Certified Azure Data Scientist Associate certification provides professionals with several tangible benefits.
First, it establishes credibility. Microsoft certifications are globally recognized and signal to employers that you have validated expertise in both cloud computing and machine learning. This can be a decisive factor when applying for jobs or seeking promotions.
Second, it enhances career opportunities. Organizations across industries are actively seeking data scientists who can operate in cloud environments. Certified professionals can pursue roles such as machine learning engineer, AI consultant, or cloud data analyst.
Third, it improves earning potential. Data scientists are already among the highest-paid professionals in technology, and those with cloud expertise often command even higher salaries.
Finally, it builds practical expertise. The certification process emphasizes hands-on learning, ensuring that professionals can apply their knowledge to solve real-world challenges.
Preparing effectively for the exam
Preparation is key to successfully achieving this certification. A combination of structured learning and practical experience produces the best results.
Candidates should start by exploring Microsoft Learn, which offers free modules tailored to the DP-100 exam. These modules cover everything from creating Azure Machine Learning workspaces to deploying models. They also include interactive labs that allow learners to practice directly in the Azure environment.
Hands-on practice is essential. Building end-to-end projects, such as training a model on a public dataset and deploying it as a web service, provides experience that cannot be replicated by theory alone.
Instructor-led courses, either online or in person, are another valuable resource. These courses provide expert guidance, structured learning paths, and opportunities to ask questions in real time.
Engaging with the data science community can also accelerate preparation. Online forums, study groups, and discussion boards allow candidates to share insights, ask questions, and learn from the experiences of others.
Lastly, practice exams are highly recommended. They simulate the real test environment, helping candidates identify knowledge gaps, manage time effectively, and build confidence.
Career opportunities and industry applications
Data science skills combined with Azure expertise open doors to a wide range of industries.
In healthcare, Azure data scientists develop predictive models to improve patient outcomes, analyze medical imaging, and optimize hospital operations.
In finance, they build systems for fraud detection, credit scoring, and algorithmic trading.
Retail organizations use their skills to create recommendation engines, analyze customer behavior, and manage supply chains more effectively.
Manufacturing companies rely on predictive maintenance models to reduce downtime and improve efficiency.
Technology firms use Azure-based machine learning to power AI-driven products, optimize services, and manage large volumes of data efficiently.
Emerging trends in Azure data science
The demand for Azure data scientists continues to grow as businesses increasingly adopt AI-driven solutions. Emerging trends include:
Responsible AI: Organizations are focusing on ethical AI, ensuring models are unbiased, transparent, and compliant with regulations
MLOps: Integrating machine learning with DevOps practices allows continuous deployment, monitoring, and improvement of AI models
AI for business insights: Companies are using predictive analytics and recommendation systems to optimize operations and enhance customer experiences
Automation of machine learning workflows: AutoML and other automation tools reduce repetitive tasks, allowing data scientists to focus on problem-solving and model optimization
The Microsoft Certified Azure Data Scientist Associate certification equips professionals with the skills needed to thrive in a data-driven, cloud-focused world. It validates the ability to design, build, deploy, and manage machine learning models using Azure, providing a foundation for career advancement and professional recognition. With growing demand for AI and data science expertise, this certification serves as a gateway to exciting opportunities across multiple industries, empowering professionals to drive innovation and business success.
Setting Up Azure Machine Learning Environments
The foundation of effective data science in Azure starts with a properly configured environment. Azure Machine Learning provides a flexible ecosystem for managing data, compute resources, and model workflows. Creating an efficient workspace ensures that data scientists can focus on experimentation rather than infrastructure management.
An Azure Machine Learning workspace serves as a centralized hub where datasets, experiments, pipelines, and models are organized. It provides access control, versioning, and collaboration tools, allowing teams to work simultaneously on projects. Workspaces can be linked to Azure subscriptions and resource groups, ensuring that costs and permissions are properly managed.
When setting up an environment, it is important to select the right compute resources. Azure offers several options including local compute, cloud-based virtual machines, and GPU clusters. The choice depends on the scale of the data and the complexity of the models being developed. Using GPU-enabled clusters can dramatically reduce training time for deep learning models, while smaller projects may only require standard CPU-based compute resources.
Proper environment setup also involves selecting the appropriate development tools. Azure provides both a visual interface through Azure Machine Learning Studio and a code-centric environment via Jupyter notebooks. Using notebooks allows data scientists to integrate Python libraries, run experiments programmatically, and automate workflows. Studio, on the other hand, offers drag-and-drop features for those who prefer a low-code approach.
Data Collection and Integration
A critical step in any machine learning project is collecting and integrating data. Azure supports a variety of data sources including SQL databases, Azure Data Lake, Cosmos DB, and external APIs. Azure Data Factory can be used to automate the movement and transformation of data across different sources, ensuring it is centralized and accessible for analysis.
Once data is collected, it is important to understand its structure and quality. Data scientists should inspect for missing values, outliers, and inconsistencies. Azure provides tools for profiling datasets, generating summary statistics, and visualizing distributions. Identifying data issues early helps prevent errors during model training and improves overall model performance.
Integration also involves combining multiple datasets when necessary. Joining structured tables or merging unstructured datasets, such as images or text, can provide richer features for modeling. Azure supports various formats and provides connectors to facilitate these operations without extensive manual coding.
Data Cleaning and Preprocessing
Raw data is rarely ready for machine learning. Preprocessing is essential to ensure that algorithms can effectively learn patterns. Common preprocessing steps include handling missing values, scaling numerical features, encoding categorical variables, and removing duplicates.
Missing data can be addressed by imputation, replacing null values with averages, medians, or most frequent values. In some cases, it may be appropriate to remove rows or columns with excessive missing data. Scaling numerical features ensures that algorithms are not biased by feature magnitude, particularly in distance-based models like k-nearest neighbors or clustering.
Categorical variables need to be encoded to numerical formats. Techniques such as one-hot encoding or label encoding are commonly used. One-hot encoding creates binary columns for each category, while label encoding assigns a unique integer to each category. Choosing the correct encoding method depends on the algorithm being used.
Outliers can skew model performance and may need to be removed or adjusted. Azure provides visualization tools like boxplots and scatter plots to identify anomalies. Feature selection is also part of preprocessing, where irrelevant or redundant features are removed to improve efficiency and reduce the risk of overfitting.
Feature Engineering and Selection
Feature engineering is the process of transforming raw data into meaningful inputs for machine learning models. It is a critical factor in achieving high model performance. Features should capture the underlying patterns in the data while remaining interpretable and relevant to the problem domain.
Creating new features from existing data can improve predictive power. For example, extracting date components like day, month, and year or calculating ratios and differences between variables can reveal patterns not immediately visible. Text data can be converted into numerical representations using techniques such as TF-IDF or word embeddings.
Feature selection involves identifying the most important variables for a model. Techniques like correlation analysis, mutual information, and recursive feature elimination can help reduce dimensionality. Reducing the number of features not only improves model performance but also simplifies interpretation and reduces computational costs.
Azure Machine Learning provides automated tools for feature engineering and selection. AutoML can suggest transformations and select features based on cross-validation performance, saving time while maintaining accuracy.
Model Selection and Training
Once the data is prepared, the next step is selecting the appropriate model. The choice of algorithm depends on the task—classification, regression, clustering, or recommendation. Azure supports a wide range of algorithms, including decision trees, logistic regression, random forests, gradient boosting, support vector machines, and neural networks.
Training a model involves feeding the algorithm with labeled data to learn patterns and relationships. Hyperparameter tuning is a key part of this process. Adjusting parameters like learning rate, depth of a tree, or number of neurons in a layer can significantly impact model accuracy. Azure Machine Learning provides automated hyperparameter tuning capabilities to optimize models efficiently.
Validation is also critical during training. Splitting data into training, validation, and test sets ensures that models generalize well to unseen data. Techniques like k-fold cross-validation allow for robust assessment of performance and reduce the risk of overfitting.
Model Evaluation and Metrics
Evaluating model performance is essential to ensure that it meets business objectives. The choice of evaluation metric depends on the type of problem. For classification tasks, metrics like accuracy, precision, recall, F1-score, and ROC-AUC are commonly used. Regression tasks often rely on mean absolute error, mean squared error, or R-squared.
Azure provides built-in tools to calculate these metrics and visualize model performance. Confusion matrices, precision-recall curves, and residual plots help data scientists understand where models succeed and where improvements are needed. Monitoring model performance during training also helps detect issues like overfitting or underfitting early.
Model Deployment in Azure
After training and validation, models are deployed to production environments. Azure allows models to be deployed as web services or APIs, making them accessible to applications or external users. Deployment involves creating an inference pipeline that accepts input data, runs predictions, and returns results in real time.
Azure Machine Learning supports multiple deployment options. Models can run on Azure Kubernetes Service for scalable, high-availability deployments or on Azure Container Instances for smaller-scale workloads. Continuous integration and delivery pipelines ensure that updates and retraining can be implemented smoothly.
Monitoring deployed models is essential to maintain performance. Data drift, where the distribution of incoming data changes over time, can degrade accuracy. Azure provides monitoring tools to detect drift, track performance metrics, and trigger retraining as needed.
Practical Applications of Azure Machine Learning
The combination of data science skills and Azure Machine Learning capabilities unlocks a wide range of applications across industries. In healthcare, predictive models can identify patients at risk of complications or readmission. Retail companies can use recommendation engines to enhance customer experience and increase sales. Financial institutions rely on machine learning for fraud detection, credit scoring, and portfolio optimization.
Manufacturing industries leverage predictive maintenance models to reduce downtime and improve operational efficiency. Technology companies integrate AI-driven features into software applications, automate processes, and optimize resource allocation. The versatility of Azure Machine Learning allows organizations to address diverse challenges using a single, scalable platform.
Best Practices for Azure Data Scientists
To maximize the impact of machine learning solutions, professionals should follow several best practices:
Document datasets, preprocessing steps, model parameters, and evaluation results to ensure reproducibility
Collaborate with stakeholders to ensure models address business objectives
Monitor deployed models regularly and retrain when performance drops
Apply ethical AI principles, ensuring fairness, transparency, and privacy
Leverage automation tools like AutoML for efficiency while maintaining human oversight
Following these practices ensures that AI initiatives are reliable, scalable, and aligned with organizational goals.
Successfully leveraging Azure Machine Learning requires more than technical knowledge. It demands a comprehensive approach encompassing environment setup, data collection and preprocessing, feature engineering, model training and evaluation, and deployment. By mastering these areas, Azure Data Scientists can deliver solutions that generate tangible business value.
The Microsoft Certified Azure Data Scientist Associate certification validates these skills, ensuring that professionals are equipped to navigate the entire machine learning lifecycle. As organizations continue to embrace AI and cloud computing, the demand for skilled Azure Data Scientists will continue to grow, opening doors to rewarding career opportunities across industries.
Introduction to advanced machine learning concepts
Once data scientists are proficient in basic machine learning workflows in Azure, the next step is exploring advanced techniques to improve model performance and handle complex datasets. Advanced machine learning encompasses deep learning, ensemble methods, reinforcement learning, and natural language processing. These approaches allow data scientists to solve challenging problems that go beyond linear regression or basic classification.
Azure Machine Learning supports a variety of frameworks for implementing advanced models. TensorFlow, PyTorch, and Scikit-learn can be integrated seamlessly, enabling data scientists to experiment with cutting-edge algorithms. Understanding these advanced techniques is essential for building scalable, accurate, and efficient AI solutions.
Deep learning in Azure
Deep learning involves neural networks with multiple layers that can automatically learn hierarchical representations from data. This approach is particularly effective for image recognition, speech processing, and natural language understanding.
In Azure, deep learning workflows can leverage GPU-enabled compute clusters for faster training. Using frameworks such as TensorFlow or PyTorch, data scientists can design convolutional neural networks for image classification, recurrent neural networks for sequential data, or transformer models for language processing. Azure also supports pre-trained models and transfer learning, which reduces training time and improves accuracy when data is limited.
Key considerations for deep learning include proper network architecture design, activation functions, loss functions, and optimization algorithms. Azure provides tools to monitor training progress, visualize learning curves, and adjust hyperparameters efficiently.
Ensemble methods and model stacking
Ensemble learning combines multiple models to improve predictive performance. Techniques such as bagging, boosting, and stacking are commonly used to reduce bias, variance, and overfitting.
Bagging, or bootstrap aggregating, involves training multiple models on different subsets of the data and averaging their predictions. Random forests are a popular example of bagging. Boosting sequentially trains models, focusing on data points that previous models misclassified. Gradient boosting machines and XGBoost are widely used boosting algorithms.
Stacking combines predictions from multiple models as inputs to a higher-level meta-model. This approach leverages the strengths of different algorithms and often results in superior performance. Azure Machine Learning supports ensemble workflows and provides automated tools for hyperparameter optimization and model selection in ensemble setups.
Natural language processing in Azure
Natural language processing (NLP) allows machines to understand, interpret, and generate human language. NLP applications include sentiment analysis, text classification, chatbot development, and machine translation.
Azure offers pre-built NLP services through Azure Cognitive Services, including text analytics, language understanding (LUIS), and translation APIs. For custom models, Azure Machine Learning allows data scientists to build and train NLP models using libraries like Hugging Face Transformers.
Text data requires preprocessing steps such as tokenization, lemmatization, stop word removal, and vectorization. Feature engineering for text involves converting words into numerical representations, such as TF-IDF, word embeddings, or contextual embeddings from transformers. Properly preprocessed data ensures that NLP models can extract meaningful patterns and achieve high performance.
Reinforcement learning
Reinforcement learning (RL) is a machine learning paradigm where agents learn by interacting with an environment and receiving feedback in the form of rewards or penalties. RL is particularly useful for decision-making tasks, robotics, game AI, and optimization problems.
Azure supports RL frameworks through integration with Python libraries such as OpenAI Gym and RLlib. Data scientists can design environments, define reward structures, and train agents using simulation data. Deploying RL models in production often involves continuous monitoring and retraining to adapt to changing environments.
Reinforcement learning differs from supervised learning because it focuses on long-term strategy rather than immediate predictions. Successful implementation requires careful definition of rewards, constraints, and exploration-exploitation trade-offs.
AutoML and model automation
Automated machine learning (AutoML) streamlines the process of selecting models, tuning hyperparameters, and performing feature engineering. AutoML is particularly useful when multiple algorithms and parameter combinations need to be tested to identify the best-performing model.
Azure Machine Learning provides a robust AutoML framework that supports classification, regression, and time-series forecasting. AutoML evaluates candidate models using cross-validation and selects the optimal configuration based on chosen metrics. It also generates explanations for model predictions, aiding interpretability.
AutoML reduces the time and effort required to experiment with complex workflows, allowing data scientists to focus on business problem definition, data quality, and model interpretation. However, human oversight remains essential to ensure that automated pipelines produce meaningful and ethical outcomes.
Hyperparameter tuning and optimization
Model performance often depends on the choice of hyperparameters, which control aspects of learning algorithms such as learning rate, regularization strength, tree depth, or number of neurons. Hyperparameter optimization is critical to achieving accurate and robust models.
Azure Machine Learning provides tools for automated hyperparameter tuning, including grid search, random search, and Bayesian optimization. These techniques systematically explore combinations of parameters to identify the settings that maximize model performance.
Proper hyperparameter tuning requires careful planning, computational resources, and evaluation metrics aligned with business objectives. Azure’s scalable compute resources allow experimentation with large search spaces and complex models efficiently.
Model interpretability and explainability
As AI solutions become more integrated into business operations, understanding model decisions is increasingly important. Model interpretability and explainability help stakeholders trust predictions, meet regulatory requirements, and identify potential biases.
Techniques for model interpretation include feature importance analysis, SHAP (SHapley Additive exPlanations), LIME (Local Interpretable Model-agnostic Explanations), and partial dependence plots. Azure provides built-in tools for generating explanations and visualizing how input features influence model predictions.
Transparent models are especially critical in sensitive domains such as healthcare, finance, and legal services, where decisions can have significant real-world consequences.
Monitoring and managing advanced models
Deploying advanced machine learning models in production requires ongoing monitoring. Azure offers tools to track model performance, detect data drift, and schedule retraining when needed.
Data drift occurs when the statistical properties of incoming data change over time, potentially degrading model accuracy. Monitoring metrics and using automated alerts allow data scientists to address these issues proactively. Model retraining pipelines can be integrated into continuous deployment workflows to maintain reliability and efficiency.
Proper monitoring ensures that advanced models continue to deliver value and remain aligned with business objectives, even as data and environments evolve.
Real-world applications of advanced techniques
Advanced machine learning techniques enable a wide range of real-world applications.
In healthcare, deep learning models analyze medical images for early disease detection. Reinforcement learning optimizes treatment protocols in simulation-based environments.
In finance, ensemble methods improve credit risk prediction and fraud detection. NLP is used for analyzing customer communications and regulatory documents.
Retail companies employ recommendation systems, powered by deep learning and AutoML, to personalize shopping experiences. Predictive maintenance in manufacturing leverages reinforcement learning and time-series forecasting to minimize equipment downtime.
In technology, AI-driven personalization, anomaly detection, and predictive analytics rely on advanced models to enhance products and optimize operations.
Best practices for implementing advanced models in Azure
Implementing advanced models effectively requires attention to several best practices:
Ensure data quality and relevance before applying complex algorithms
Choose the appropriate model complexity relative to the available data and problem domain
Use AutoML and hyperparameter tuning judiciously to balance efficiency and oversight
Monitor model performance continuously and implement retraining pipelines
Maintain transparency and interpretability to build trust and comply with regulations
Collaborate with business stakeholders to ensure models align with organizational goals
Following these practices allows data scientists to maximize the impact of advanced machine learning techniques while mitigating risks.
Mastering advanced machine learning techniques in Azure opens new possibilities for solving complex problems and driving business value. Deep learning, ensemble methods, NLP, reinforcement learning, and AutoML expand the toolkit available to data scientists, enabling sophisticated predictions, optimizations, and insights.
The Microsoft Certified Azure Data Scientist Associate certification equips professionals with the skills to implement these advanced methods, manage models in production, and interpret results effectively. By combining technical expertise with Azure’s scalable infrastructure, data scientists can create high-impact AI solutions that address evolving organizational needs and deliver measurable outcomes.
Introduction to model deployment
Building machine learning models is only part of a data scientist’s journey. To deliver real business value, models must be deployed into production environments where they can provide actionable insights. Azure Machine Learning offers robust deployment options that allow data scientists to operationalize models efficiently while maintaining scalability, security, and performance.
Deployment involves taking a trained and validated model and making it accessible to applications, users, or other services. Azure supports deployment through APIs, web services, containers, and edge devices. Effective deployment ensures that predictions are delivered reliably, consistently, and quickly.
Understanding deployment options in Azure
Azure provides multiple deployment options to suit different use cases:
Azure Kubernetes Service (AKS): Ideal for high-scale production workloads. AKS allows models to run in a containerized, orchestrated environment, ensuring high availability and scalability.
Azure Container Instances (ACI): Suitable for smaller-scale deployments or testing environments. ACI provides a simple way to run models in containers without managing infrastructure.
Azure Functions: Enables serverless deployment for lightweight, event-driven model inference. Functions are useful for tasks that require integration with other Azure services and low-latency responses.
Edge deployment: For applications requiring inference on devices rather than the cloud, Azure IoT Edge allows models to run on edge devices while maintaining connectivity and monitoring.
Selecting the appropriate deployment option depends on workload requirements, latency constraints, and expected traffic. Azure provides flexibility to transition between deployment types as business needs evolve.
Creating inference pipelines
Inference pipelines automate the process of making predictions from deployed models. They define the sequence of steps from input data processing to model inference and output delivery. Pipelines can include data validation, preprocessing, batch scoring, and post-processing tasks.
Azure Machine Learning supports pipeline creation using both visual and code-first approaches. Data scientists can orchestrate workflows that handle complex transformations, apply multiple models in sequence, and store predictions in databases or cloud storage.
Pipelines improve consistency, reduce errors, and enable repeatable model inference in production environments. They are particularly useful in scenarios involving large volumes of data or complex decision-making processes.
Continuous integration and continuous deployment (CI/CD)
CI/CD practices in machine learning, often referred to as MLOps, are essential for maintaining model quality and reliability. MLOps integrates software engineering principles with data science workflows to enable automated testing, deployment, and monitoring.
In Azure, CI/CD pipelines can be implemented using Azure DevOps or GitHub Actions. These pipelines automate tasks such as:
Testing model performance and accuracy
Packaging models into containers
Deploying models to production environments
Triggering retraining when data drift is detected
Automated pipelines reduce human error, speed up deployment cycles, and ensure that models remain aligned with evolving data and business requirements.
Monitoring model performance in production
Once models are deployed, continuous monitoring is crucial. Azure provides tools to track model performance metrics, detect data drift, and identify anomalies in predictions.
Monitoring focuses on three key areas:
Prediction accuracy: Comparing predicted outcomes with actual results to identify performance degradation
Data drift: Detecting changes in input data distributions that can impact model effectiveness
Operational metrics: Monitoring latency, throughput, and system resource usage to ensure efficient deployment
Alerts can be configured to notify data scientists of issues, enabling timely intervention. Monitoring ensures that models continue to deliver reliable insights over time.
Managing model retraining and versioning
Models in production can lose accuracy due to changing data patterns or business conditions. Retraining involves updating models with new data to maintain performance. Azure Machine Learning supports automated retraining workflows, allowing models to be refreshed on a scheduled basis or triggered by performance degradation.
Versioning is critical for tracking changes in models and maintaining reproducibility. Azure automatically manages model versions, storing metadata, training data references, and configuration details. Version control ensures that past models can be reproduced or rolled back if needed, supporting auditability and compliance requirements.
Implementing responsible AI in production
Responsible AI is a core consideration when deploying machine learning models. It ensures fairness, transparency, privacy, and accountability in AI solutions. Azure provides tools to evaluate and mitigate bias, generate interpretability reports, and enforce data privacy standards.
Key responsible AI practices include:
Assessing model fairness by analyzing predictions across different demographic groups
Using interpretability tools to explain model decisions to stakeholders
Ensuring data is anonymized and protected in accordance with regulations
Documenting model assumptions, limitations, and ethical considerations
Responsible AI practices build trust with end-users and align with regulatory and ethical standards.
Scaling deployed models
As model usage grows, scaling becomes essential to maintain performance. Azure offers automatic scaling for AKS and ACI deployments, adjusting compute resources based on traffic and workload. This ensures low-latency predictions and high availability without manual intervention.
Scaling also involves optimizing batch processing for large datasets, distributing tasks across multiple compute nodes, and leveraging parallel inference pipelines. Proper scaling strategies improve efficiency, reduce costs, and maintain a seamless user experience.
Security and compliance in production
Deploying models in production requires attention to security and compliance. Azure provides features such as role-based access control, network isolation, encryption at rest and in transit, and auditing tools to ensure secure deployment.
Data scientists must also consider compliance with industry standards such as GDPR, HIPAA, or ISO regulations. Ensuring secure data handling and model operations protects organizations from legal and reputational risks.
Case studies and real-world examples
In healthcare, deployed models predict patient readmission risks, allowing hospitals to allocate resources effectively. Continuous monitoring and retraining ensure models remain accurate despite changes in patient demographics or treatment protocols.
In retail, recommendation engines deployed via AKS personalize customer experiences across websites and mobile apps. Data drift monitoring ensures that product suggestions remain relevant as consumer behavior evolves.
Financial institutions deploy fraud detection models that analyze transaction patterns in real time. Automated CI/CD pipelines enable rapid updates to algorithms as new fraud tactics emerge.
Manufacturing companies use predictive maintenance models deployed on IoT edge devices to reduce equipment downtime. These models continuously analyze sensor data, providing actionable insights while minimizing latency.
Best practices for deploying models in Azure
Effective deployment requires adherence to best practices:
Test models thoroughly in staging environments before production
Implement CI/CD pipelines to automate deployment and retraining
Monitor performance and detect data drift continuously
Apply responsible AI principles to ensure fairness, transparency, and compliance
Scale deployments based on demand and optimize for cost efficiency
Document deployment processes, model versions, and operational metrics for reproducibility
Following these practices ensures that machine learning models deliver sustained business value and remain robust under changing conditions.
Deploying and managing machine learning models in Azure is a critical step in transforming AI experiments into actionable business solutions. By leveraging Azure’s deployment options, inference pipelines, CI/CD practices, and monitoring tools, data scientists can operationalize models efficiently and reliably.
The Microsoft Certified Azure Data Scientist Associate certification equips professionals with the skills to handle deployment, monitoring, scaling, and responsible AI practices. Mastering these capabilities ensures that machine learning solutions continue to deliver accurate predictions, maintain trust, and create measurable impact across diverse industries.
Introduction to responsible AI
As artificial intelligence becomes central to business operations, ensuring ethical and responsible AI practices is critical. Azure data scientists are not only responsible for building accurate models but also for guaranteeing that those models are fair, transparent, and aligned with organizational and societal standards.
Responsible AI emphasizes fairness, accountability, transparency, and privacy. Organizations must ensure that models do not introduce bias, discriminate against specific groups, or produce harmful outcomes. Azure provides tools and frameworks that help data scientists evaluate models for bias, interpret predictions, and maintain compliance with regulations.
Key principles of responsible AI
Responsible AI is built on several foundational principles:
Fairness: Models should make decisions impartially, without favoring or disadvantaging certain groups.
Transparency: Decision-making processes should be explainable and interpretable to stakeholders.
Accountability: Organizations should track model ownership, performance, and operational decisions.
Privacy: Data should be handled securely, adhering to regulations and minimizing exposure of sensitive information.
Reliability: AI systems should be robust, delivering consistent performance under varying conditions.
Azure Machine Learning integrates features such as model interpretability dashboards, bias detection tools, and audit logs, enabling data scientists to incorporate these principles into their workflows.
Model governance and compliance
Model governance ensures that deployed models are managed responsibly throughout their lifecycle. Governance includes version control, access management, performance tracking, and regulatory compliance.
Azure supports governance by enabling:
Versioning of datasets, models, and pipelines for reproducibility
Role-based access control to manage permissions and protect sensitive information
Monitoring tools to detect drift, anomalies, and degradation in model performance
Audit trails for documentation and regulatory reporting
Effective governance not only mitigates risks but also builds trust among stakeholders and ensures alignment with organizational policies.
Mitigating bias in AI models
Bias in AI can occur due to unbalanced datasets, flawed feature selection, or algorithmic design. Data scientists must proactively detect and address these biases to prevent unfair outcomes.
Azure provides several tools to evaluate bias, including fairness metrics, subgroup analysis, and counterfactual testing. Techniques to mitigate bias include:
Re-sampling or weighting training data to balance representation
Removing sensitive attributes that could introduce bias
Adjusting algorithms or post-processing predictions to promote fairness
Addressing bias early in the model development lifecycle reduces the risk of unintended consequences and ensures ethical AI deployment.
Model interpretability and explainability
Interpretability allows stakeholders to understand how a model arrives at predictions. Explainable AI is essential for gaining user trust, complying with regulations, and identifying potential errors or biases in models.
Azure Machine Learning offers built-in interpretability features such as SHAP (SHapley Additive exPlanations), LIME (Local Interpretable Model-agnostic Explanations), and feature importance analysis. These tools provide insights into which features influence predictions, how changes in inputs affect outputs, and where the model may behave unpredictably.
Transparent models are especially important in regulated industries such as healthcare, finance, and legal services, where decisions have significant real-world implications.
Continuous learning and model maintenance
AI models are not static; they require ongoing monitoring and maintenance to remain accurate and relevant. Data drift, changes in business context, or shifts in user behavior can degrade model performance over time.
Azure enables automated monitoring of deployed models, tracking prediction quality, detecting drift, and triggering retraining workflows. Data scientists can schedule periodic updates, integrate retraining into CI/CD pipelines, and maintain a record of model changes to ensure reliability and reproducibility.
Continuous learning ensures that models adapt to evolving conditions and continue to deliver value to the organization.
Career pathways for Azure Data Scientists
The demand for Azure Data Scientists continues to grow across industries. Professionals with skills in cloud-based machine learning, data engineering, and AI deployment are highly sought after. Career paths can include:
Machine Learning Engineer: Focused on building, training, and optimizing models for production
AI Consultant: Advising organizations on AI strategies, responsible AI, and implementation best practices
Data Analyst/Scientist: Working with data pipelines, exploratory analysis, and predictive modeling
MLOps Engineer: Specializing in deployment, monitoring, and lifecycle management of AI models
Certification as a Microsoft Azure Data Scientist Associate strengthens professional credibility, signaling expertise in cloud-based AI and machine learning.
Industry applications and opportunities
Azure Data Scientists find opportunities across various sectors:
Healthcare: Predictive models for patient outcomes, medical imaging analysis, and operational optimization
Finance: Fraud detection, credit scoring, algorithmic trading, and regulatory reporting
Retail: Recommendation engines, demand forecasting, and customer behavior analysis
Manufacturing: Predictive maintenance, supply chain optimization, and quality control
Technology: AI-driven software features, automation, and analytics platforms
Organizations are increasingly seeking professionals who can bridge technical expertise with business insight, ensuring that AI solutions deliver measurable value.
Emerging trends in Azure data science
The field of Azure data science is evolving rapidly, driven by innovations in AI and cloud technology. Some emerging trends include:
Responsible AI adoption: Companies are integrating fairness, transparency, and accountability into all stages of AI development
Automated machine learning: AutoML and low-code solutions accelerate model development and deployment
MLOps integration: Combining DevOps principles with machine learning ensures reliable, continuous delivery of AI solutions
Edge AI deployment: Models are increasingly being deployed on devices for real-time inference without cloud dependency
Explainable AI and regulatory compliance: Emphasis on interpretability to meet legal and ethical standards
Staying updated with these trends ensures that Azure Data Scientists remain competitive and relevant in the marketplace.
Skills development and continuous learning
The rapidly evolving AI landscape requires continuous learning. Data scientists should focus on:
Enhancing proficiency in Python, R, and Azure SDKs
Learning advanced machine learning algorithms, deep learning, and reinforcement learning
Understanding MLOps practices for deployment and monitoring
Staying informed about AI ethics, governance, and responsible AI frameworks
Engaging with the Azure community, forums, and online learning platforms
Investing in skill development ensures career growth and the ability to deliver high-impact AI solutions.
Preparing for long-term career growth
Long-term success as an Azure Data Scientist requires combining technical expertise with business acumen. Professionals should:
Build a portfolio of projects showcasing end-to-end machine learning solutions
Gain experience with real-world deployments and CI/CD pipelines
Develop communication skills to explain insights to non-technical stakeholders
Stay adaptable and open to learning new tools, frameworks, and methodologies
Pursue advanced certifications and specialized courses to deepen expertise
This holistic approach ensures sustainable career advancement and the ability to make meaningful contributions to organizational success.
Conclusion
Azure Data Scientists play a pivotal role in transforming data into actionable intelligence while ensuring that AI systems are ethical, transparent, and reliable. Mastery of responsible AI principles, model governance, continuous learning, and deployment strategies equips professionals to create high-value solutions across industries.
The Microsoft Certified Azure Data Scientist Associate certification provides a structured pathway to develop these skills, opening doors to rewarding career opportunities. By embracing best practices, staying current with emerging trends, and committing to lifelong learning, Azure Data Scientists can deliver innovative, trustworthy AI solutions that drive business growth and positive societal impact.
ExamCollection provides the complete prep materials in vce files format which include Microsoft Certified: Azure Data Scientist Associate certification exam dumps, practice test questions and answers, video training course and study guide which help the exam candidates to pass the exams quickly. Fast updates to Microsoft Certified: Azure Data Scientist Associate certification exam dumps, practice test questions and accurate answers vce verified by industry experts are taken from the latest pool of questions.


Microsoft Microsoft Certified: Azure Data Scientist Associate Video Courses

Top Microsoft Certifications


























































Top Microsoft Certification Exams
- AZ-104
- AZ-305
- DP-700
- AB-100
- SC-300
- MD-102
- PL-300
- AB-900
- AI-900
- MS-102
- SC-200
- AZ-900
- SC-401
- AZ-700
- AI-102
- DP-600
- AB-730
- SC-100
- AZ-500
- AB-731
- AI-103
- GH-300
- PL-400
- SC-900
- AZ-140
- AZ-204
- DP-300
- AZ-400
- PL-600
- MS-700
- AZ-801
- AZ-800
- MB-800
- PL-200
- PL-900
- AI-300
- MB-330
- MB-310
- DP-900
- MB-820
- MB-280
- SC-500
- MB-230
- MS-721
- AI-901
- MB-700
- GH-200
- DP-800
- DP-100
- DP-420
- MB-335
- MB-500
- PL-500
- DP-750
- GH-900
- MS-900
- GH-500
- GH-100
- AZ-120
- SC-400
- MB-240
- 62-193
- 98-382
- MO-200
- DP-203
- 98-367
- 98-383
- MO-400
- MS-203
- MB-910
Site Search:




I want do this course