


Premium File
74 Q&A
$76.99$69.99
Microsoft DP-201 Exam Questions & Answers, Accurate & Verified By IT Experts
Instant Download, Free Fast Updates, 99.6% Pass Rate
74 Questions & Answers
Last Update: Jun 23, 2026
$69.99
Microsoft DP-201 Exam Screenshots
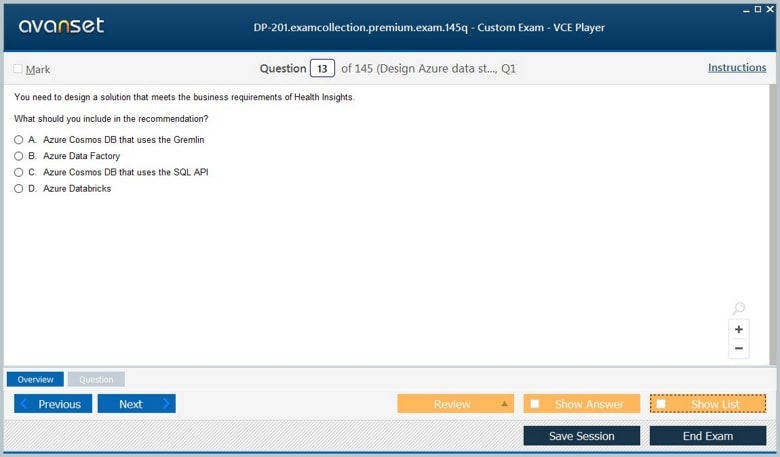
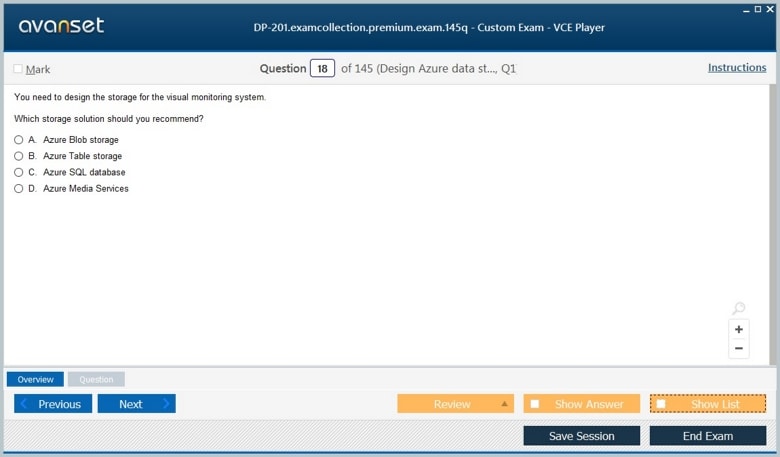
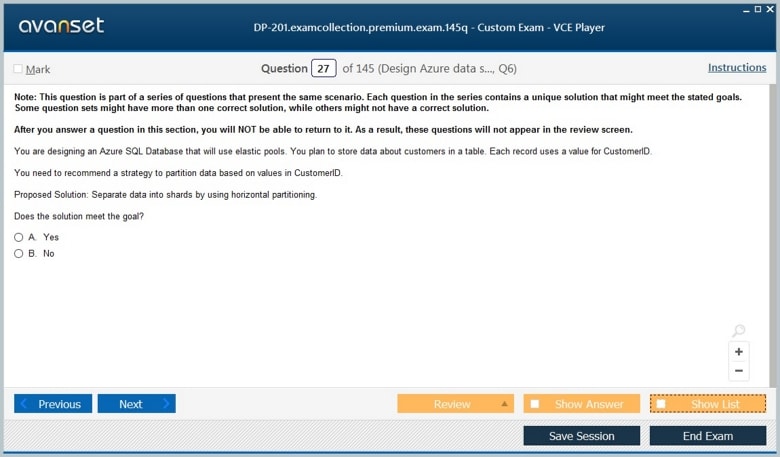
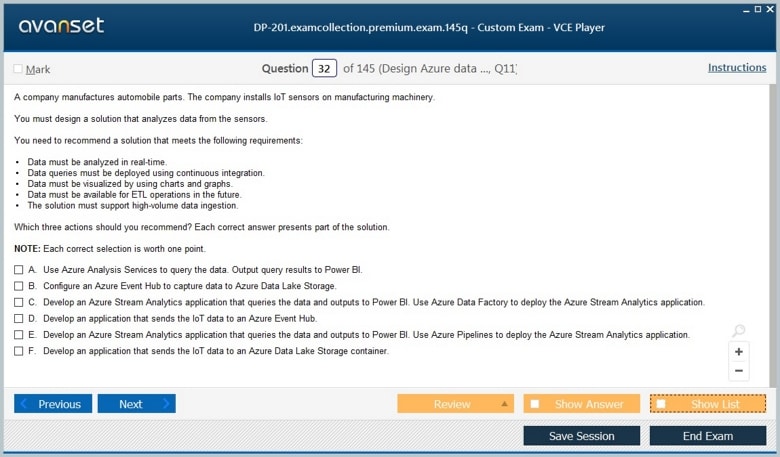
Microsoft DP-201 Practice Test Questions in VCE Format
| File | Votes | Size | Date |
|---|---|---|---|
File Microsoft.pass4sure.DP-201.v2020-02-12.by.zhangli.73q.vce |
Votes 5 |
Size 1.58 MB |
Date Feb 12, 2020 |
Microsoft DP-201 Practice Test Questions, Exam Dumps
Microsoft DP-201 (Designing an Azure Data Solution) exam dumps vce, practice test questions, study guide & video training course to study and pass quickly and easily. Microsoft DP-201 Designing an Azure Data Solution exam dumps & practice test questions and answers. You need avanset vce exam simulator in order to study the Microsoft DP-201 certification exam dumps & Microsoft DP-201 practice test questions in vce format.
The DP-201 exam was unique because it focused exclusively on the discipline of design. Unlike implementation-focused exams, its primary goal was to validate a candidate's ability to think like a data architect. This meant evaluating requirements, understanding constraints, and selecting the most appropriate combination of services to build a solution that was secure, scalable, and cost-effective. The core philosophy was not about writing code or configuring settings but about making informed architectural decisions. A professional who mastered the DP-201 content could look at a business problem and translate it into a technical blueprint for a robust data platform.
This design-first approach is more critical than ever. In the cloud, the sheer number of available services can be overwhelming. Simply knowing how to use a service is not enough; a true data engineer must know when and why to use it over other alternatives. The DP-201 exam forced candidates to justify their choices based on specific criteria like latency requirements, data consistency models, query patterns, and security postures. This skill of critical evaluation is the bedrock of effective data engineering and a central theme we will explore throughout this series, using the DP-201 syllabus as our guide.
The Azure Data Engineer Associate certification is designed for professionals who manage and maintain data on a large scale. This role involves a wide spectrum of responsibilities, starting from data ingestion and storage to processing and analysis. The data engineer is the one who builds and maintains the data pipelines that feed business intelligence dashboards, machine learning models, and other data-driven applications. They ensure that data is clean, reliable, and accessible to those who need it, such as data scientists and analysts. This role is inherently technical, requiring a strong grasp of data modeling, ETL/ELT processes, and database technologies.
The original certification path required passing both an implementation exam and a design exam, the DP-201. This structure highlighted the dual nature of the data engineering role. A data engineer must not only be able to build the solution but also possess the architectural foresight to design it correctly from the start. A poorly designed system can lead to performance bottlenecks, security vulnerabilities, and spiraling costs. Therefore, the skills once validated by DP-201 are not just a nice-to-have; they are an essential component of a competent Azure Data Engineer's toolkit.
Before diving into the complex design scenarios presented in the DP-201 curriculum, a solid foundation of prerequisite knowledge is essential. At a minimum, a candidate should have a strong command of data-related fundamentals. This includes fluency in SQL for querying and manipulating relational data. Understanding the core differences between relational (OLTP) and analytical (OLAP) workloads is also crucial. Beyond relational concepts, familiarity with non-relational or NoSQL data models, such as key-value, document, and graph, is necessary to design modern data solutions that handle unstructured and semi-structured data.
Furthermore, a basic understanding of core cloud computing and Azure concepts is assumed. Aspiring data architects should be familiar with fundamental Azure services, including compute, storage, and networking. While not a strict requirement, having passed the Azure Fundamentals exam (AZ-900) provides a very helpful baseline. This foundational knowledge ensures that when you begin to design a data solution, you understand the underlying platform on which it will be built, allowing you to make more informed decisions about security, networking, and service integration, all key components of the DP-201 skill set.
The DP-201 exam revolved around a core set of Azure data services. Understanding the purpose and primary use case for each is the first step toward designing effective solutions. Azure Data Lake Storage Gen2 serves as the foundational data lake, optimized for large-scale analytics. For relational data, the Azure SQL family, including Azure SQL Database and Azure SQL Managed Instance, offers managed database-as-a-service options. Azure Synapse Analytics (formerly Azure SQL Data Warehouse) is the premier service for enterprise data warehousing and large-scale parallel processing of structured data.
For non-relational workloads, Azure Cosmos DB is the globally distributed, multi-model database service, supporting various APIs and consistency levels. Data orchestration and movement are primarily handled by Azure Data Factory, which allows you to build complex ETL and ELT pipelines. For real-time data ingestion and processing, Azure Event Hubs provides a high-throughput data streaming platform, often paired with Azure Stream Analytics for real-time analysis. Finally, Azure Databricks offers a powerful Apache Spark-based analytics platform for large-scale data processing and machine learning. Mastering these services was key for DP-201.
The DP-201 exam was structured into three main knowledge domains, each carrying a different weight. The largest domain, "Design Azure data storage solutions," typically accounted for 40-45% of the exam. This area tested your ability to choose the right storage technology, whether it be a data lake, a relational database, or a NoSQL store, based on specific requirements. It also covered the design of the data models, partitioning strategies, and data distribution for optimal performance. This was the heart of the exam, focusing on the foundational layer of any data platform.
The second domain, "Design data processing solutions," covered about 25-30% of the questions. This section focused on the architectural patterns for both batch and real-time data processing. You would be expected to design solutions using services like Azure Data Factory, Azure Databricks, and Azure Stream Analytics. The third domain, "Design for data security and compliance," also made up 25-30% of the exam. This critical area covered everything from securing data at rest and in transit to designing data policies, managing identities, and ensuring regulatory compliance.
A fundamental skill for any data architect, and a key concept within the DP-201 framework, is data modeling. This is the process of structuring data to meet specific business requirements. For relational systems, this involves understanding normalization and denormalization. Normalization helps reduce data redundancy and improve data integrity, which is ideal for transactional systems. In contrast, denormalization, often used in analytical systems, combines tables to reduce join operations and improve query performance, forming the basis for dimensional models like star and snowflake schemas.
In the non-relational world, data modeling takes on different forms. For a document database like Azure Cosmos DB, you might embed related data within a single document to optimize for read-heavy operations, avoiding costly joins. For a key-value store, the design of the key itself becomes a critical part of the model. The DP-201 exam required candidates to analyze access patterns and requirements to recommend the appropriate data model, recognizing that the right model is the one that makes data access efficient, scalable, and aligned with the application's needs.
One of the most frequent decisions a data architect makes is choosing between a relational (SQL) and a non-relational (NoSQL) data store. This was a central theme of the DP-201 exam. Relational databases, like Azure SQL, excel where data has a predictable structure and strong consistency is required. They are the traditional choice for transactional applications (OLTP) where ACID (Atomicity, Consistency, Isolation, Durability) guarantees are paramount. Their structured query language and mature tooling make them a reliable option for many business applications.
Non-relational databases, on the other hand, are designed for scenarios that relational databases handle less gracefully. This includes managing large volumes of unstructured or semi-structured data, the need for horizontal scalability, and applications requiring high velocity and flexibility. Services like Azure Cosmos DB provide options for various data models and tunable consistency levels, making them ideal for modern applications like IoT, gaming, and social media. A key DP-201 skill was the ability to analyze requirements and determine which of these two broad categories, or which specific service within them, was the best fit for the job.
Designing for scale was a non-negotiable aspect of the DP-201 exam. In the cloud, it is not enough to build a solution that works for the current data volume; it must be designed to handle future growth gracefully. This involves selecting services that can scale and configuring them correctly. For example, when designing with Azure SQL Database, you need to choose the right service tier and understand the difference between scaling up (increasing the resources of a single server) and scaling out (distributing the load across multiple servers).
Similarly, when designing with a service like Azure Cosmos DB or Azure Synapse Analytics, partitioning is a critical concept. A good partitioning strategy distributes data and processing load evenly across physical partitions, preventing "hot spots" that can degrade performance. The choice of a partition key has a profound impact on the scalability and cost of the solution. The DP-201 exam would present scenarios where you had to analyze query patterns and data characteristics to recommend an optimal partitioning strategy, demonstrating your ability to design for high performance at scale.
To master the concepts once covered by the DP-201 exam, a structured approach is essential. Begin by thoroughly reviewing the official documentation for the core Azure data services. Pay special attention to the "concepts" and "architecture" sections, as these provide the "why" behind the technology, which is crucial for design-level thinking. Supplement this with hands-on labs. While DP-201 was a design exam, practical experience building small-scale solutions provides invaluable context and reinforces theoretical knowledge. You cannot effectively design a solution you have never worked with.
Next, focus on case studies and architectural reference guides. These resources show how different Azure services are combined to solve real-world business problems. Analyze these architectures and ask yourself why certain choices were made. Why was Azure Databricks chosen over Azure Data Factory's mapping data flows? Why was Cosmos DB selected instead of Azure SQL? This type of critical analysis is precisely the skill that the DP-201 exam was designed to measure and is essential for success in any data engineering design role.
The foundation of many modern data platforms is the data lake, and in Azure, the premier service for this is Azure Data Lake Storage Gen2 (ADLS Gen2). A key skill tested in the DP-201 framework was the ability to design an effective data lake structure. ADLS Gen2 is not just a blob container; it's built on top of Azure Blob Storage but adds a hierarchical namespace. This feature allows it to organize data into a familiar directory and file structure, which is massively beneficial for analytical query engines like Apache Spark. It enables more efficient data access and management.
When designing a data lake solution, architects must consider several factors. A common best practice is to structure the lake into zones, such as a raw or bronze zone for ingesting data in its original format, a refined or silver zone for cleansed and conformed data, and a curated or gold zone for aggregated data ready for consumption by business users. Furthermore, a DP-201 candidate would need to decide on file formats, such as Parquet or Delta Lake, which offer performance benefits like columnar storage and schema enforcement, and design an appropriate folder structure to enable efficient data pruning and querying.
While data lakes are central to big data analytics, relational databases remain the workhorse for transactional systems and structured data management. The DP-201 exam required a deep understanding of Azure's relational offerings to make the right design choice. The main options are Azure SQL Database, Azure SQL Managed Instance, and SQL Server on Azure VMs. Each serves a different purpose. Azure SQL Database is a fully managed platform-as-a-service (PaaS) offering, ideal for new cloud-native applications that do not require full SQL Server compatibility or operating system access.
Azure SQL Managed Instance, in contrast, is designed for modernizing existing SQL Server applications. It provides near-100% compatibility with the on-premises SQL Server engine, making it perfect for "lift and shift" migrations with minimal code changes. It combines the rich features of SQL Server with the benefits of a PaaS offering. Finally, running SQL Server on an Azure Virtual Machine provides maximum control, giving you full access to the underlying OS. A DP-201 architect must weigh factors like management overhead, feature compatibility, and cost to recommend the best relational platform for a given scenario.
For applications that require massive scale, global distribution, and flexible schemas, Azure Cosmos DB is the go-to service. A significant portion of the DP-201 storage design domain focused on this powerful NoSQL database. Designing a solution with Cosmos DB involves more than just choosing the service; it requires careful consideration of its core architectural components. The first major decision is selecting the right API. Cosmos DB offers multiple APIs, including Core (SQL), MongoDB, Cassandra, Gremlin, and Table, allowing developers to use familiar tools and drivers.
The most critical design decision for Cosmos DB is the choice of the partition key. This key determines how data is logically and physically distributed. A well-chosen partition key spreads requests evenly across all partitions, ensuring scalability and preventing performance bottlenecks. A poor choice can lead to "hot partitions" that throttle the entire system. A DP-201 candidate would be expected to analyze the data's read and write patterns to select a partition key with high cardinality that evenly distributes the workload, demonstrating a deep understanding of scalable NoSQL design.
For large-scale enterprise analytics and business intelligence, Azure Synapse Analytics is the core component. The DP-201 exam required architects to understand how to design data warehouses that can handle petabytes of data and complex analytical queries. Synapse Analytics integrates several capabilities, but its core for data warehousing is the dedicated SQL pool. This feature uses a Massively Parallel Processing (MPP) architecture to distribute data and query processing across multiple compute nodes, enabling incredible performance on large datasets.
A key design task for a Synapse dedicated SQL pool is choosing the right table distribution strategy. There are three options: hash, round-robin, and replicated. Hash-distributed tables are partitioned on a specific column, co-locating data with the same key on the same compute node, which is ideal for large fact tables to minimize data movement during joins. Round-robin distribution spreads data evenly but randomly, suitable for staging tables. Replicated tables create a full copy of the table on each compute node, perfect for small dimension tables. Selecting the correct distribution is fundamental to achieving high query performance, a classic DP-201 design challenge.
Designing for analytical workloads, a core DP-201 skill, is fundamentally different from designing for transactional systems. While transactional systems often use a highly normalized model to ensure data integrity and reduce redundancy, analytical systems prioritize query performance. The most common approach for this is dimensional modeling, which typically involves creating a star schema or a snowflake schema. A star schema consists of a central fact table, containing quantitative data (measures), surrounded by dimension tables that provide descriptive context.
The fact table contains foreign keys that link to the dimension tables. This denormalized structure minimizes the number of joins required for complex queries, making them much faster. A snowflake schema is a variation where dimensions are further normalized into multiple related tables. While this can reduce data storage, it often comes at the cost of query performance due to the need for more joins. A data architect must analyze the trade-offs between storage, performance, and complexity to design the most effective dimensional model for their data warehouse.
A critical aspect of designing cost-effective data storage solutions, and a key consideration for DP-201, is data lifecycle management. Not all data is accessed with the same frequency. As data ages, it is typically accessed less often. Azure Storage provides different access tiers to help manage costs based on this principle. The hot tier is optimized for frequently accessed data, offering the lowest access costs but the highest storage costs. The cool tier is for infrequently accessed data, with lower storage costs but higher access costs. The archive tier offers the lowest storage cost but with data retrieval times of several hours.
An effective design involves creating policies to automatically move data between these tiers as it ages. For example, log data from the last 30 days might be kept in the hot tier for immediate analysis. After 30 days, it could be moved to the cool tier for occasional queries. After 90 days, it could be moved to the archive tier for long-term compliance retention. Designing and implementing these lifecycle management policies ensures that you are only paying for high-performance storage when you actually need it, which is a crucial element of a well-architected cloud solution.
The essence of the DP-201 exam was its focus on scenario-based questions. You would be presented with a set of business and technical requirements and asked to design the optimal solution. For data storage, this means applying your knowledge to a concrete problem. For instance, if a scenario described a global e-commerce application needing low-latency reads and writes for user profiles and shopping carts, Azure Cosmos DB would be a strong candidate due to its global distribution and multi-master write capabilities. Its flexible schema is also well-suited for product catalog data.
Conversely, if a scenario involved a financial services company needing to migrate its existing on-premises SQL Server-based reporting database with complex stored procedures and triggers, Azure SQL Managed Instance would be the ideal choice. It offers the required compatibility to minimize migration effort. If the goal was to build a centralized repository for petabytes of raw IoT sensor data for future analysis, Azure Data Lake Storage Gen2 would be the correct answer. The ability to read requirements, identify key constraints, and map them to the features of a specific service is the ultimate test of a DP-201-level data architect.
Batch processing is a fundamental data engineering workload, dealing with large volumes of data at rest. In the Azure ecosystem, Azure Data Factory (ADF) is the primary service for orchestrating these batch workflows. The DP-201 exam required a thorough understanding of how to design robust, scalable, and manageable data pipelines using ADF. This goes beyond simply dragging and dropping activities onto a canvas. It involves designing pipelines that are parameterized, allowing for reusability and dynamic execution based on input variables.
A well-designed ADF solution also incorporates proper control flow logic, using activities like 'ForEach' loops for iteration and 'If Condition' for branching. Error handling and logging are also critical design considerations. Pipelines should be built to be resilient, capable of retrying failed activities and logging failures for later analysis. Furthermore, an architect must decide on the appropriate Integration Runtime. The Azure IR is used for cloud-to-cloud data movement, while the Self-Hosted IR is required for accessing data in on-premises or virtual network-secured environments. These design choices are central to creating an effective batch processing system.
While Azure Data Factory is excellent for orchestration and data movement, for complex, large-scale data transformations, Azure Databricks is often the more powerful choice. Based on Apache Spark, Databricks provides a high-performance, distributed computing engine that excels at processing massive datasets. A key DP-201 design decision was knowing when to use ADF's native capabilities (like Mapping Data Flows) versus when to delegate the heavy lifting to a Databricks notebook or job. Databricks is typically chosen for tasks requiring custom code, advanced analytics, or machine learning model training.
When designing a solution with Databricks, the architect must consider cluster configuration. This includes selecting the right VM sizes for the driver and worker nodes, and configuring autoscaling to balance cost and performance. The design also involves structuring the code within notebooks for clarity and maintainability. A popular architectural pattern often designed in conjunction with Databricks is the Medallion Architecture. This involves creating bronze (raw), silver (cleansed), and gold (aggregated) tables, typically using Delta Lake, to progressively refine data and prepare it for consumption, a core concept for modern data platform design.
The modern data landscape is increasingly characterized by real-time data streams from sources like IoT devices, web applications, and social media feeds. The DP-201 curriculum placed a strong emphasis on designing solutions to handle this streaming data. The first challenge is ingestion. Azure offers two primary services for this purpose: Azure Event Hubs and Azure IoT Hub. While similar, they serve distinct use cases. Azure Event Hubs is a general-purpose, high-throughput data streaming platform. It is designed to ingest millions of events per second from any source.
Azure IoT Hub, on the other hand, is specifically built for connecting and managing IoT devices. It includes all the capabilities of Event Hubs but adds critical features for IoT scenarios, such as per-device identity, device management, and bidirectional communication (cloud-to-device messaging). A DP-201 level architect must be able to analyze the requirements of a streaming scenario. If the solution requires device management or sending commands back to devices, IoT Hub is the correct choice. If it is a pure data telemetry firehose, Event Hubs is the more appropriate and cost-effective option.
Once streaming data has been ingested by Event Hubs or IoT Hub, it needs to be processed in near real-time. Azure Stream Analytics (ASA) is a fully managed service designed for this purpose. It allows you to write SQL-like queries to analyze data on the fly as it arrives. A key part of designing a solution with ASA, and a topic frequently covered in DP-201 scenarios, is the concept of windowing functions. Since a data stream is theoretically infinite, you need to define bounded windows of time over which to perform aggregations.
ASA supports several window types. Tumbling windows are fixed-size, non-overlapping time intervals, useful for creating periodic reports (e.g., the number of clicks every 5 seconds). Hopping windows are fixed-size but can overlap, which is useful for finding trends over a rolling period. Sliding windows trigger an output whenever a new event occurs within a specific time duration. Choosing the right windowing function based on the business requirements is a fundamental aspect of designing an effective real-time processing job. The architect must also design the inputs (the stream source) and outputs (where the processed data goes, such as Power BI, a SQL database, or Cosmos DB).
Many advanced data platforms need to support both real-time and batch processing on the same data. Two common architectural patterns address this need: the Lambda architecture and the Kappa architecture. The Lambda architecture, a classic pattern relevant to DP-201, consists of three layers. A batch layer pre-computes historical views of the data for accuracy. A speed (or real-time) layer processes data as it arrives to provide low-latency, up-to-the-minute views. A serving layer then combines the results from both the batch and speed layers to answer queries.
The Kappa architecture is a simplification of Lambda. It proposes that all processing, both historical and real-time, can be done in a single stream processing engine. This is made possible by modern streaming platforms that can reprocess a stream from the beginning, effectively allowing the stream itself to serve as the single source of truth. In an Azure context, a Lambda architecture might use Azure Data Factory for the batch layer and Azure Stream Analytics for the speed layer. A Kappa architecture might use a single, powerful engine like Azure Databricks with Structured Streaming to handle all processing tasks. An architect must understand the trade-offs in complexity, cost, and latency between these two patterns.
Not all data processing tasks require a large, persistent cluster. For event-driven, short-lived tasks, serverless compute can be a highly efficient and cost-effective design choice. Azure Functions is the primary serverless compute service in Azure. A DP-201 candidate should know when to incorporate Azure Functions into a data processing design. They are an excellent fit for lightweight data transformations. For example, a function could be triggered whenever a new file is uploaded to a storage account. This function could then read the file, perform a simple validation or enrichment, and write the result to another location.
This event-driven model decouples different parts of the architecture and allows for highly scalable, granular processing. Instead of running a large pipeline on a schedule to process all new files, a small function runs immediately for each individual file. This can lead to lower latency and reduced costs, as you only pay for the compute time you actually consume. Knowing how to integrate Azure Functions with services like Event Grid, Event Hubs, and Azure Storage is a key skill for designing modern, responsive data solutions.
Protecting data when it is stored on disk, known as data at rest, is a fundamental security requirement for any data platform. A core competency for the DP-201 skill set was designing a multi-layered security strategy for stored data. In Azure, the first layer is typically Storage Service Encryption (SSE). Most Azure storage services, including Azure Blob Storage, Data Lake Storage, and Azure SQL, enable encryption at rest by default using platform-managed keys. This provides a baseline level of protection without any user configuration.
For enhanced control and compliance, organizations can opt for customer-managed keys (CMK). With CMK, the encryption keys are stored in Azure Key Vault, a secure key management service. This gives the organization full control over the key lifecycle, including the ability to rotate or revoke keys. A DP-201 level architect must know when CMK is required, such as for meeting specific regulatory standards like PCI-DSS. Additionally, for relational databases like Azure SQL and Azure Synapse Analytics, Transparent Data Encryption (TDE) is used to encrypt the entire database, log files, and backups at rest, providing another crucial layer of defense.
In addition to protecting data at rest, it is equally important to secure data as it moves between different components of a solution or from users to the cloud. This is known as securing data in transit. The standard mechanism for this is using Transport Layer Security (TLS), which encrypts the data channel. All Azure services support TLS for their public endpoints, and it is a best practice to enforce the use of a secure connection, rejecting any attempts to connect over an unencrypted channel. The DP-201 exam would expect a candidate to know how to enforce this policy on services like Azure SQL Database and Azure Storage.
Beyond TLS, a more robust method for securing data in transit within the Azure network is to avoid the public internet altogether. This is achieved using network security features like Virtual Network (VNet) service endpoints and private endpoints. Service endpoints provide a secure and direct connection to Azure services from a VNet. Private endpoints are even more secure, as they create a network interface within your VNet with a private IP address that maps to a specific Azure service instance. This effectively brings the service into your private network, ensuring that all traffic remains on the secure Microsoft backbone network.
A well-designed data solution must be built on a secure network foundation. The DP-201 curriculum required architects to design network architectures that isolate and protect sensitive data systems. The primary tool for this is the Azure Virtual Network (VNet), which allows you to create a private, isolated network in the cloud. Data services like Azure SQL Managed Instance and Azure Databricks can be deployed directly into a VNet, making them inaccessible from the public internet by default.
To control traffic flow within and between VNets, Network Security Groups (NSGs) are used. NSGs act as a basic firewall, allowing you to define inbound and outbound traffic rules based on IP address, port, and protocol. For more advanced protection, an Azure Firewall can be deployed to provide centralized traffic filtering and threat intelligence. A common design pattern is the hub-spoke topology, where a central "hub" VNet contains shared services like the firewall, and various "spoke" VNets containing the application workloads peer with the hub. This provides centralized security control and network segmentation.
Controlling who can access data and what they can do with it is arguably the most critical aspect of data security. In Azure, identity and access management is centralized through Azure Active Directory (Azure AD). The DP-201 exam emphasized the importance of using modern authentication and authorization methods. A key principle is to move away from using shared secrets like connection strings or account keys whenever possible. Instead, the preferred method is to use Azure AD identities.
Managed Identities are a powerful feature that provides an Azure service with an automatically managed identity in Azure AD. This allows a service, like an Azure Function or a VM, to authenticate to another service, like Azure Key Vault or Azure Storage, without needing any credentials stored in its code or configuration. For user access, Role-Based Access Control (RBAC) is used to grant permissions. RBAC allows you to assign specific roles (like Reader, Contributor, or Owner) to users or groups at a defined scope (like a subscription, resource group, or individual resource), enforcing the principle of least privilege.
In addition to controlling access, it is often necessary to protect sensitive data within a database from privileged users who may have query access, such as developers or database administrators. The DP-201 framework included designing solutions for data privacy. Azure SQL Database and Azure Synapse Analytics offer features to help with this. Dynamic Data Masking (DDM) is a policy-based feature that obfuscates sensitive data in the result set of a query. For example, you can create a mask to show only the last four digits of a credit card number, while the full number remains unchanged in the database.
For more granular control, Row-Level Security (RLS) can be implemented. RLS allows you to control which users can see which rows in a table based on their identity. You define a security predicate, which is a function that is implicitly added as a WHERE clause to every query. For example, in a sales table, you could implement a policy that ensures sales representatives can only see the rows corresponding to their own customers. These features are critical for building multi-tenant applications and meeting privacy regulations.
Modern organizations operate under a complex web of regulatory requirements, such as the General Data Protection Regulation (GDPR) and the Health Insurance Portability and Accountability Act (HIPAA). A data architect must design solutions that meet these compliance standards. This involves not only securing the data but also being able to audit access, track data lineage, and classify sensitive information. The DP-201 exam required an awareness of these design considerations.
Microsoft Purview (formerly Azure Purview) is a unified data governance service that helps with these challenges. It can automatically scan and classify data across your entire data estate, whether on-premises or in the cloud. It can identify sensitive data like personal identifiable information (PII) and apply sensitivity labels. It also provides a business glossary to define common terms and data lineage visualization to track how data moves and transforms through your pipelines. Designing a data platform with governance in mind from the start, and knowing how to incorporate tools like Purview, is a hallmark of a senior data architect.
Go to testing centre with ease on our mind when you use Microsoft DP-201 vce exam dumps, practice test questions and answers. Microsoft DP-201 Designing an Azure Data Solution certification practice test questions and answers, study guide, exam dumps and video training course in vce format to help you study with ease. Prepare with confidence and study using Microsoft DP-201 exam dumps & practice test questions and answers vce from ExamCollection.
Purchase Individually
Microsoft DP-201 Video Course

Top Microsoft Certifications


























































Top Microsoft Certification Exams
Site Search:

SPECIAL OFFER: GET 10% OFF

Pass your Exam with ExamCollection's PREMIUM files!
SPECIAL OFFER: GET 10% OFF
Use Discount Code:
MIN10OFF
A confirmation link was sent to your e-mail.
Please check your mailbox for a message from support@examcollection.com and follow the directions.

Download Free Demo of VCE Exam Simulator
Experience Avanset VCE Exam Simulator for yourself.
Simply submit your e-mail address below to get started with our interactive software demo of your free trial.
The dumps from this platform cover all the key concepts and the newest types of questions, which you might find in the actual test. Besides that, the answers to each of these questions have been explained well to ensure you understand the concepts tested better to pass the exam much easier.
I used the study materials offered by ExamCollection while preparing for DP-200 and scored high marks! I just hope these VCE files will be helpful too. Now, I practice with them and see that they are also high-quality just like the previous ones. I can’t wait for the day I’ll clear DP-201 and earn the Microsoft Certified Azure Data Engineer Associate credential!
The practice tests for the DP-201 test are excellent for practicing with. This was my second trial and I passed! I had used other learning resources during my first attempt and failed. Then my colleague informed me about these files, and I immediately downloaded them. After practicing with them, I sat for the test and performed excellently. I am grateful to ExamCollection!
The braindumps for the DP-201 exam are more than 90% valid. Almost all the questions contained in them closely matched those I found in the real test. They actually exceeded my expectations in terms of the test results! I am sure all of you will find them useful too.