


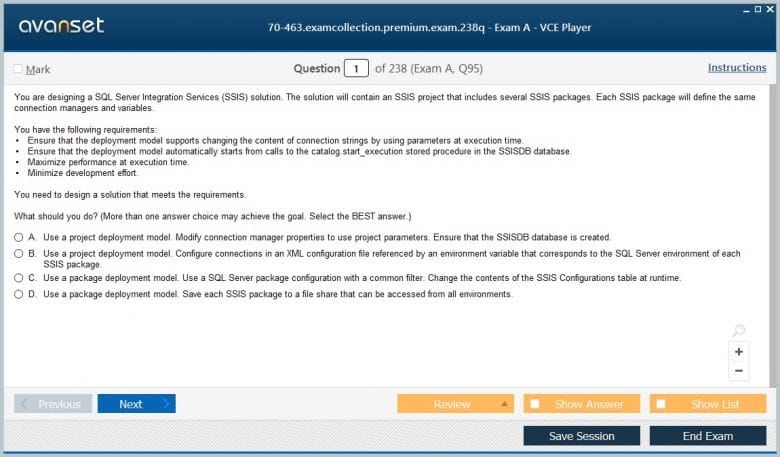
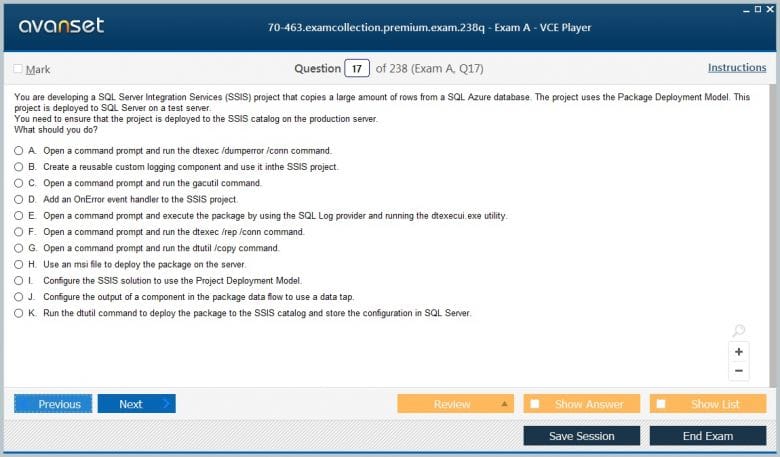
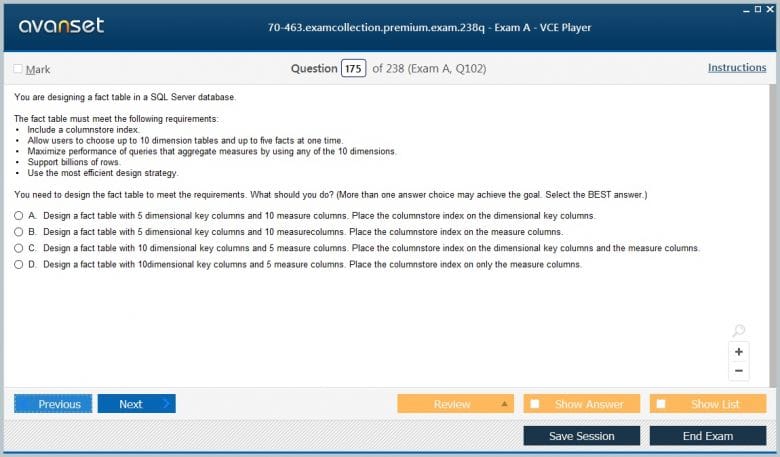
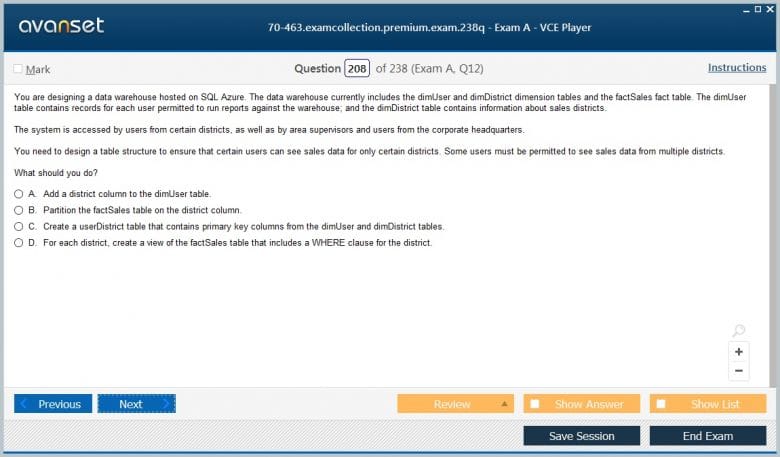
Premium File
50 Q&A
$76.99$69.99
Microsoft MCSA 70-463 Exam Questions & Answers, Accurate & Verified By IT Experts
Instant Download, Free Fast Updates, 99.6% Pass Rate
50 Questions & Answers
Last Update: Jul 02, 2026
$69.99
Microsoft MCSA 70-463 Exam Screenshots
Microsoft MCSA 70-463 Practice Test Questions in VCE Format
| File | Votes | Size | Date |
|---|---|---|---|
File Microsoft.Braindumps.70-463.v2014-09-20.by.ANTONINA.214q.vce |
Votes 35 |
Size 3.02 MB |
Date Sep 20, 2014 |
File Microsoft.Actualcerts.70-463.v2014-04-26.by.Stacey.70q.vce |
Votes 14 |
Size 2.05 MB |
Date Apr 26, 2014 |
File Microsoft.Braindumps.70-463.v2014-01-23.by.Aussie.216q.vce |
Votes 181 |
Size 3.03 MB |
Date Jan 23, 2014 |
File Microsoft.Passguide.70-463.v2013-08-12.by.Aussie.125q.vce |
Votes 27 |
Size 995.6 KB |
Date Aug 14, 2013 |
Archived VCE files
| File | Votes | Size | Date |
|---|---|---|---|
File Microsoft.Braindumps.70-463.v2014-12-11.by.Monroe.210q.vce |
Votes 2 |
Size 2.96 MB |
Date Dec 11, 2014 |
File Microsoft.Certdumps.70-463.v2014-06-07.by.MILDRED.195q.vce |
Votes 5 |
Size 4.54 MB |
Date Jun 07, 2014 |
File Microsoft.Actual-Exams.70-463.v2014-05-20.by.Fredricka.100q.vce |
Votes 3 |
Size 846.15 KB |
Date May 20, 2014 |
File Microsoft.Examsheets.70-463.v2014-03-13.by.Alma.58q.vce |
Votes 4 |
Size 1.61 MB |
Date Mar 13, 2014 |
File Microsoft.Braindumps.70-463.v2014-02-22.by.Bashne.214q.vce |
Votes 5 |
Size 3.02 MB |
Date Feb 22, 2014 |
File Microsoft.Testking.70-463.v2013-08-14.by.Appata.122q.vce |
Votes 4 |
Size 933.34 KB |
Date Aug 14, 2013 |
File Microsoft.BrainDump.70-463.v2013-02-22.by.PeterPan.122q.vce |
Votes 3 |
Size 933.65 KB |
Date Feb 24, 2013 |
File Microsoft.Compilation.70-463.v2013-01-18.by.7thfreak.111q.vce |
Votes 1 |
Size 2.49 MB |
Date Jan 20, 2013 |
Microsoft MCSA 70-463 Practice Test Questions, Exam Dumps
Microsoft 70-463 (MCSA Implementing a Data Warehouse with Microsoft SQL Server 2012/2014) exam dumps vce, practice test questions, study guide & video training course to study and pass quickly and easily. Microsoft 70-463 MCSA Implementing a Data Warehouse with Microsoft SQL Server 2012/2014 exam dumps & practice test questions and answers. You need avanset vce exam simulator in order to study the Microsoft MCSA 70-463 certification exam dumps & Microsoft MCSA 70-463 practice test questions in vce format.
The Microsoft 70-463 Exam, titled "Implementing a Data Warehouse with Microsoft SQL Server," was a cornerstone certification for data professionals. It served as a rigorous validation of the skills required to design, build, and maintain a data warehouse, a critical component of any business intelligence strategy. Although this specific exam is retired, the principles it tested—dimensional modeling, ETL processes, data quality, and master data management—are more relevant than ever, forming the bedrock of modern data engineering and analytics. This series will provide a comprehensive guide to these timeless concepts, using the structure of the 70-463 Exam as a framework for building a powerful and in-demand skill set.
In this foundational first part, we will set the stage for your learning journey. We will begin by decoding the 70-463 Exam, understanding its original purpose and the professionals it was designed for. We will then explore the vital role of a data warehouse developer in transforming raw data into strategic assets. We will break down the core concepts of data warehousing, compare the leading design methodologies, and introduce the key components of the Microsoft Business Intelligence stack. Finally, we will discuss the enduring value of these skills and outline a roadmap for beginning your preparation.
The Microsoft 70-463 Exam was a professional-level certification test designed to validate the technical skills of business intelligence and data warehouse developers. It was a key exam in the pathway to achieving the Microsoft Certified Solutions Associate (MCSA): SQL Server and the more advanced Microsoft Certified Solutions Expert (MCSE): Data Platform or Business Intelligence certifications. The exam's primary focus was on the practical implementation of a data warehouse using the tools available within the Microsoft SQL Server ecosystem, particularly SQL Server Integration Services (SSIS).
This exam was targeted at BI developers, ETL developers, and data engineers whose main responsibility was to extract data from various source systems, transform it into a clean and consistent format, and load it into a central data warehouse. The content assumed that candidates had a solid understanding of relational databases and T-SQL, and then built upon that foundation to test their skills in data modeling for analytical purposes, creating robust ETL packages, and ensuring the quality and integrity of the data being loaded.
Successfully passing the 70-463 Exam demonstrated a comprehensive and highly practical skill set. It signified that you could design and implement a dimensional data model, the standard for data warehousing. It proved you could build complex, high-performance ETL processes using SSIS to populate the warehouse. Furthermore, it certified your ability to implement solutions for data cleansing using Data Quality Services (DQS) and to manage critical business data using Master Data Services (MDS). The certification was a clear signal of competence in the end-to-end process of building a data warehouse.
The exam format consisted of a mix of question types, including multiple-choice, drag-and-drop, and detailed case studies. The case studies were particularly important, as they presented a realistic business scenario and required the candidate to make design and implementation decisions based on the provided requirements. This format was designed to ensure that certified professionals could not only recall technical facts but could also apply their knowledge to solve real-world data warehousing challenges.
A data warehouse developer, often called a Business Intelligence (BI) developer or an ETL developer, plays a pivotal role in an organization's data strategy. Their core responsibility is to bridge the gap between raw, operational data and the polished, insightful information that business leaders need to make strategic decisions. They are the architects and builders of the data infrastructure that powers analytics, reporting, and data science. The skills tested in the 70-463 Exam are the fundamental competencies required for this critical role.
The primary task of a data warehouse developer is to design and implement the ETL (Extract, Transform, Load) process. This involves writing code and using tools like SSIS to connect to a wide variety of source systems, such as sales databases, marketing applications, and customer relationship management (CRM) systems. They then extract the relevant data, cleanse and standardize it, reshape it to fit an analytical model, and finally load it into the central data warehouse. This ETL process is the heart of the data warehousing workflow.
Beyond just moving data, the developer is also responsible for the logical and physical design of the data warehouse itself. They work with business analysts to understand the key performance indicators (KPIs) and metrics the business wants to track. Based on these requirements, they design the fact tables and dimension tables that will store the data in a way that is optimized for fast and easy querying and reporting.
Ultimately, the data warehouse developer is a problem solver. When a report shows incorrect numbers or a nightly data load fails, they are the ones who must investigate and resolve the issue. This requires a deep understanding of the entire data pipeline, strong T-SQL skills, and a methodical approach to troubleshooting. They are the guardians of the data's quality and reliability, ensuring that the business can trust the information it is using to make critical decisions.
To understand the material covered in the 70-463 Exam, you must first grasp the fundamental purpose of a data warehouse. A data warehouse is a large, centralized repository of data that is specifically designed for querying and analysis rather than for transaction processing. This is the key difference between an Online Analytical Processing (OLAP) system, like a data warehouse, and an Online Transaction Processing (OLTP) system, like a typical sales or inventory database.
OLTP systems are designed for speed and efficiency in handling a large number of small, concurrent transactions, such as creating a new sales order or updating a customer's address. Their data models are highly normalized to avoid redundancy and ensure data integrity. However, this normalization makes them very difficult and slow to query for analytical purposes, as you would need to join many tables together to answer a simple business question.
This is the problem that a data warehouse, an OLAP system, is designed to solve. It pulls data from all the various OLTP systems and reorganizes it into a structure that is optimized for analysis. The data is denormalized and structured around business processes, making it easy to ask questions like "What were the total sales for each product category in the northern region last quarter?" A data warehouse provides a single, consolidated source of truth for the entire organization.
The data in a warehouse is typically historical, integrated, non-volatile, and time-variant. This means it contains data from many years, it is cleaned and made consistent, it is not updated in real-time but is loaded periodically (e.g., nightly), and every record is associated with a specific point in time. The 70-463 Exam was designed to test your ability to build a system that adheres to these core principles.
When it comes to designing a data warehouse, there are two primary schools of thought, and the 70-463 Exam would have expected you to be familiar with both. These methodologies are named after their creators, Ralph Kimball and Bill Inmon. They represent two different approaches to building the enterprise data warehouse.
Bill Inmon, often called the "father of the data warehouse," advocates for a top-down approach. In this model, you first build a centralized Enterprise Data Warehouse (EDW) that is highly normalized, similar to an OLTP database. This normalized EDW acts as the single, authoritative source of all corporate data. From this central repository, you then create smaller, department-specific data marts. These data marts are denormalized and structured for specific analytical needs, but they are all fed from the consistent, centralized EDW. This approach emphasizes data integration and integrity at the core.
Ralph Kimball, on the other hand, promotes a bottom-up approach based on dimensional modeling. In this methodology, you do not start with a large, centralized model. Instead, you build the data warehouse as a collection of individual data marts, each one focused on a specific business process, such as sales, inventory, or marketing. Each data mart is built using a simple, highly denormalized structure called a star schema. The "enterprise data warehouse" in the Kimball world is simply the combination of all these individual, conformed data marts. This approach emphasizes speed to delivery and ease of use for business users.
The 70-463 Exam, and the Microsoft BI stack in general, is heavily aligned with the Kimball methodology. The concepts of dimensional modeling, star schemas, and fact and dimension tables are central to the curriculum. While both approaches have their merits, a deep understanding of Kimball's dimensional modeling techniques is essential for success.
The 70-463 Exam was specifically focused on implementing a data warehouse using the tools provided within the Microsoft Business Intelligence (BI) stack. A key part of your preparation is to understand the role of each of the core components in this ecosystem. These tools are designed to work together to provide a complete, end-to-end solution for data warehousing and business intelligence.
The foundation of the stack is the SQL Server relational database engine. This is where the physical data warehouse is created and stored. As a developer, you use your T-SQL skills to create the tables, indexes, and other database objects that make up your data warehouse schema. SQL Server is optimized for handling the large volumes of data and the complex queries that are characteristic of a data warehousing workload.
The workhorse for the ETL process, and the primary focus of the 70-463 Exam, is SQL Server Integration Services (SSIS). SSIS is a graphical, drag-and-drop tool for building high-performance data integration and transformation workflows. You use SSIS to create "packages" that extract data from source systems, perform complex transformations on it in memory, and then load it into your data warehouse.
Once the data is in the warehouse, SQL Server Analysis Services (SSAS) can be used to build analytical models, or "cubes," on top of the data. These models pre-aggregate the data and provide a very fast and user-friendly way for business users to perform complex analysis. Finally, SQL Server Reporting Services (SSRS) is the tool used to create and distribute paginated reports and dashboards based on the data in either the data warehouse or the SSAS cubes.
In a world that is rapidly moving to the cloud, studying for a retired exam based on an on-premises version of SQL Server might seem counterintuitive. However, the skills validated by the 70-463 Exam are remarkably durable and directly transferable to the most modern cloud data platforms. The specific tool names may have changed, but the underlying concepts of data warehousing and ETL have not.
The principles of dimensional modeling—designing fact and dimension tables and building star schemas—are universal. This methodology is the standard for data modeling in cloud data warehouses like Azure Synapse Analytics, Google BigQuery, and Snowflake. A deep understanding of how to structure data for analysis is a skill that is independent of the platform and is in extremely high demand for roles like data engineer and analytics engineer.
Similarly, the skills you gain from mastering SQL Server Integration Services (SSIS) are directly applicable to modern cloud-based ETL tools. Microsoft's flagship cloud ETL service, Azure Data Factory, has a feature called the SSIS Integration Runtime, which allows you to lift and shift your existing SSIS packages to the cloud and run them with minimal changes. Furthermore, the visual, pipeline-based approach of Azure Data Factory is conceptually very similar to the control flow and data flow of SSIS.
By studying the curriculum of the 70-463 Exam, you are not learning an obsolete technology. You are learning the fundamental, first principles of data engineering. You are mastering the "what" and the "why" of transforming raw data into reliable business intelligence. This foundational knowledge will make it much easier for you to learn and adapt to the new tools and platforms that are continually emerging in the rapidly evolving world of data.
To create a structured plan for studying the concepts of the 70-463 Exam, it is invaluable to use the original exam objectives as a guide. These objectives provide a logical breakdown of the skills required to be a competent data warehouse developer. The objectives can be grouped into four major domains, which will form the basis of this article series.
The first major domain was designing and implementing the data warehouse itself. This covered the logical and physical design of the database schema. The objectives would have included designing fact and dimension tables, understanding granularity, implementing surrogate keys, and handling slowly changing dimensions. This is the architectural foundation of the entire solution.
The second and largest domain was focused on extracting and transforming data, primarily using SQL Server Integration Services (SSIS). This covered the full spectrum of ETL development, from creating SSIS packages and connecting to data sources, to implementing complex data flow transformations, to loading the data into the data warehouse. This is where the bulk of the development work lies.
A third key domain was centered on data quality. This moved beyond just moving data and into the realm of cleansing and standardizing it. This included objectives on installing and configuring Data Quality Services (DQS), creating a knowledge base, and using the DQS components within an SSIS package to cleanse data as part of the ETL process.
Finally, the fourth domain covered the implementation of a master data management solution using Master Data Services (MDS). This included objectives on designing the MDS model, creating entities and attributes, and loading and managing the master data. By following these four domains, you can build a comprehensive skill set that aligns perfectly with the requirements of a modern data engineering role.
After setting the stage with the foundational concepts of data warehousing, we now turn to the architectural blueprint of the solution: the data model. The way data is structured in a data warehouse is fundamentally different from how it is structured in a transactional system, and mastering this new way of thinking is a prerequisite for success on the 70-463 Exam. The design of the data warehouse schema is the most critical step in the entire process, as it directly impacts the usability, performance, and scalability of the business intelligence platform.
In this second part of our series, we will perform a deep dive into the art and science of dimensional modeling, the methodology championed by Ralph Kimball and the primary focus of the 70-463 Exam. We will dissect the core components of this model: fact tables and dimension tables. We will explore the critical concepts of granularity, keys, and hierarchies. We will also tackle one of the most important and frequently tested topics: the handling of Slowly Changing Dimensions (SCDs). Finally, we will compare schema designs and discuss the physical implementation in SQL Server.
The 70-463 Exam approached data modeling from a very practical, implementation-focused perspective. The exam questions were designed to ensure that a certified professional could not only define a fact table or a dimension table but could also make intelligent design decisions based on a given set of business requirements. You would be expected to analyze a business process, identify the key metrics and their descriptive attributes, and translate that understanding into a well-structured dimensional model, typically a star schema.
A central theme of the exam's data modeling section would have been the clear distinction between measurable business events (the facts) and the context that describes those events (the dimensions). The exam would have tested your ability to correctly identify which pieces of data belong in a fact table versus a dimension table. For example, in a sales data mart, the "quantity sold" and "total price" are facts, while the "product name," "customer city," and "transaction date" are dimensional attributes.
The exam would have also heavily emphasized the handling of changes in dimensional data over time. The concept of Slowly Changing Dimensions (SCDs) is a cornerstone of dimensional modeling, and the 70-463 Exam would have required you to know the different SCD types (especially Type 1 and Type 2) and understand the trade-offs of each. You would need to know how to design your tables and ETL processes to correctly maintain the history of these changes.
Finally, the exam's perspective would have included the physical implementation of the model in SQL Server. This moves from the logical design to the concrete CREATE TABLE statements. This includes choosing the correct data types, defining primary and foreign key relationships, and implementing performance-enhancing features like indexes. The goal was to validate the entire skill set, from conceptual design to physical creation.
The dimensional model, which is the core of the 70-463 Exam curriculum, is built upon two fundamental types of tables: fact tables and dimension tables. Understanding the distinct purpose of each is the first and most important step in learning how to design a data warehouse.
A dimension table is a table that contains the descriptive attributes of your business. It is used to answer the "who, what, where, when, why, and how" questions. For a retail sales business, you would have dimension tables for DimProduct, DimCustomer, DimStore, and DimDate. The DimProduct table would contain columns like ProductName, ProductCategory, and ProductBrand. The DimCustomer table would have columns like CustomerName, CustomerCity, and CustomerState. Dimension tables are typically wide (many columns) but relatively short (fewer rows).
A fact table, on the other hand, is the table that contains the measurements, metrics, or "facts" of a business process. It is the central table in a dimensional model. For a retail sales business, the main fact table would be FactSales. This table would contain numeric columns that represent the key performance indicators (KPIs) of the sales process, such as QuantitySold, UnitPrice, and TotalSaleAmount. Fact tables are typically narrow (few columns) but very deep (many, many rows, often billions).
The fact table is connected to the dimension tables through foreign key relationships. The FactSales table would have foreign keys that link to the primary keys of the DimProduct, DimCustomer, DimStore, and DimDate tables. This simple, star-like structure is called a star schema. It is highly denormalized and optimized for fast and easy querying.
One of the most important design decisions you will make when creating a fact table, and a key concept for the 70-463 Exam, is defining its granularity. The "grain" of a fact table specifies the level of detail that is represented by a single row in the table. It is a declaration of exactly what each row measures. Defining the grain is the first step in fact table design, and all subsequent design choices must be consistent with this grain.
For example, in a retail sales data warehouse, you could choose to have the grain of your FactSales table be "one row per individual sales transaction line item." This is a very fine, or atomic, grain. Each row would represent a single product on a single customer receipt. Alternatively, you could choose a coarser grain, such as "one row per sales transaction," where each row would represent the total value of an entire customer receipt.
The choice of grain is a trade-off. A finer, more atomic grain provides the maximum amount of detail and flexibility for analysis. With a line-item grain, you can analyze sales by individual product. However, a finer grain also means that your fact table will have many more rows, which will require more storage and could potentially lead to slower query performance if not designed correctly.
A coarser grain, like one row per day per store, will result in a much smaller fact table. However, you lose a significant amount of detail. With a daily grain, you can no longer analyze sales by individual customer or transaction. The best practice, and the approach emphasized by the Kimball methodology and the 70-463 Exam, is to always strive to capture data at the most atomic grain possible. You can always aggregate atomic data up to a higher level, but you can never disaggregate a summary back down to the details.
Designing effective dimension tables is a critical skill for a data warehouse developer and a core topic for the 70-463 Exam. A well-designed dimension table provides rich, descriptive context for the facts and is easy for users to understand and query. One of the most important elements of a dimension table is its primary key. While the source system might have a natural or business key for an entity (like a product SKU or an employee ID), the best practice in a data warehouse is to create a new, artificial key called a surrogate key.
A surrogate key is typically a simple integer that is automatically generated when a new row is inserted into the dimension table. This surrogate key is then used as the primary key of the dimension table and as the foreign key in the fact table. There are several advantages to using surrogate keys. They are small and efficient for the database to join on. More importantly, they allow you to properly handle Slowly Changing Dimensions, as they provide a unique identifier for each version of a dimension record.
The columns in a dimension table are called its attributes. The goal is to create rich dimension tables with many descriptive, text-based attributes. For a DimProduct table, you would include not just the product name, but also its category, subcategory, brand, color, size, and any other characteristic that a business user might want to use to slice and dice the sales data. This denormalization is intentional and is a key feature of dimensional modeling.
Dimension tables can also contain hierarchies. A hierarchy is a logical structure that defines levels of aggregation. For example, in a DimDate table, you would have attributes for the specific date, the month, the quarter, and the year. This creates a natural hierarchy that allows users to easily roll up their analysis from the daily level to the monthly, quarterly, or yearly level. The 70-463 Exam would have expected you to be able to design a dimension table with these key elements.
Perhaps the single most important technical concept in dimension table design, and a guaranteed topic on the 70-463 Exam, is the management of Slowly Changing Dimensions, or SCDs. Dimensional attributes are not always static; they can change over time. For example, a customer might move to a new city, or a product might be reassigned to a new category. The question is, how should the data warehouse handle these changes? There are several standard techniques, known as SCD types.
The simplest approach is SCD Type 1, which is to simply overwrite the old value with the new value. If a customer moves from New York to Los Angeles, you would just update the City column in their record in the DimCustomer table. This approach is easy to implement, but it has a major drawback: you lose all history. All of the customer's past sales will now appear as if they occurred in Los Angeles, which is not accurate.
The most common and powerful approach is SCD Type 2. In this method, you do not overwrite the old record. Instead, you treat the change as creating a new version of the customer. You would expire the old customer record (perhaps by setting an EndDate column) and insert a new record with a new surrogate key for the same customer, but with the updated city. You would also have columns like StartDate and IsCurrent to identify the currently active version. This preserves the full history, but it is more complex to implement in the ETL process.
A less common approach is SCD Type 3. In this method, you add a new column to the dimension table to store the previous value. For example, you might have columns for CurrentCity and PreviousCity. This allows you to track one historical change, but it does not scale for multiple changes and is rarely used in practice. The 70-463 Exam would have required you to be an expert in the differences between these types, especially Type 1 and Type 2.
Just as there are different ways to handle dimensions, there are also different types of fact tables, a key concept for the 70-463 Exam. The most common type is the transactional fact table. This is the type we have discussed so far, where each row corresponds to a single, discrete event or transaction. A transactional fact table is the most flexible and detailed type.
Another type is the periodic snapshot fact table. In this model, each row represents the state of something at a specific, regular point in time, such as the end of a day, week, or month. A good example is a daily inventory fact table. Each row would record the quantity on hand for a specific product in a specific store at the close of business each day. This is very useful for analyzing trends and performance over time.
A third type is the accumulating snapshot fact table. This type of table is used to model processes that have a well-defined beginning and end, with predictable steps in between. A good example is an order fulfillment process. A single row in the fact table might represent a sales order and have columns for the date the order was placed, the date it was shipped, and the date it was delivered. This allows for easy analysis of the duration and lag between the different milestones in a process.
The numeric columns in a fact table are called measures. Measures can be additive, meaning they can be summed up across all dimensions (e.g., SalesAmount). They can be semi-additive, meaning they can be summed across some dimensions but not others (e.g., InventoryBalance, which you can sum across products but not across time). Or they can be non-additive, meaning they cannot be summed at all (e.g., a percentage or a ratio). The 70-463 Exam would expect you to know these distinctions.
With a solid data model designed, the next and most labor-intensive phase of building a data warehouse is to populate it with data. This is the domain of ETL—Extract, Transform, and Load. For the Microsoft BI stack, and therefore for the 70-463 Exam, the primary tool for this task is SQL Server Integration Services (SSIS). SSIS is a powerful and flexible platform for building enterprise-grade data integration and workflow solutions. A deep, practical understanding of SSIS is the single most important skill required to pass the 70-463 Exam.
This third part of our series will provide a comprehensive guide to the core features and techniques of SSIS as they apply to data warehousing. We will start by dissecting the fundamental architecture of an SSIS package, distinguishing between the Control Flow and the Data Flow. We will then explore the essential components for extracting data from various sources, performing in-memory transformations, and loading the clean data into our data warehouse. We will also cover advanced topics like making packages dynamic and building in robust error handling and logging, all of which are critical competencies for the exam.
The 70-463 Exam approached SQL Server Integration Services from the perspective of a data warehouse developer. The focus was not on every obscure feature of the tool, but on the practical application of SSIS to solve the specific challenges of ETL. The exam questions would have required you to design and troubleshoot SSIS packages that could efficiently extract data from typical source systems, perform the necessary cleansing and conforming transformations, and load the data into a star schema.
A central concept tested would have been the ability to manage a complete ETL workflow. This is more than just a single data pump. A typical nightly load involves multiple steps that must be executed in a specific order, such as preparing the staging tables, loading the dimension tables first, and then loading the fact table. The exam would have required you to know how to use the SSIS Control Flow to orchestrate these steps and to handle failures gracefully.
The exam would have also heavily emphasized the Data Flow Task. This is where the real data transformation happens. You would be expected to be an expert in using the various transformation components to solve common ETL problems. For example, you would need to know how to use the Lookup transformation to find the surrogate key for a given business key, how to use the Conditional Split to route rows based on data quality checks, and how to use the Derived Column to create new data fields.
Finally, the 7_0-463 Exam_ would have stressed the importance of building packages that are not only functional but also maintainable and configurable. This includes the use of variables and parameters to avoid hard-coding values like connection strings, and the implementation of robust logging and error handling to make the packages easier to troubleshoot when they fail in a production environment.
To master SSIS, you must first understand the fundamental architecture of an SSIS package. Every SSIS package is composed of two main parts: the Control Flow and the Data Flow. The 70-463 Exam would have required you to have a crystal-clear understanding of the distinct purpose of each.
The Control Flow is the brain and orchestrator of the package. It defines the overall workflow and the order in which individual tasks are executed. The Control Flow consists of tasks and precedence constraints. Tasks are the individual units of work, such as an "Execute SQL Task" to run a SQL statement, a "File System Task" to move a file, or, most importantly, a "Data Flow Task." Precedence constraints are the green and red arrows that connect the tasks, defining the execution logic (e.g., "if Task A succeeds, then run Task B").
The Data Flow is where the actual ETL magic happens. A Data Flow Task in the Control Flow is a container for a data flow pipeline. The Data Flow is designed to move and transform large volumes of data in memory, making it extremely fast and efficient. The Data Flow consists of three types of components: Sources, which are used to extract data from various systems; Transformations, which are used to modify, cleanse, and reshape the data in-memory; and Destinations, which are used to load the transformed data into its final target.
It is critical to remember this separation. The Control Flow manages the high-level workflow, while the Data Flow handles the low-level, row-by-row data transformations. A single SSIS package can have multiple Data Flow Tasks within its Control Flow. For example, you might have one Data Flow Task to load your DimProduct table and another, separate Data Flow Task to load your DimCustomer table.
The "E" in ETL stands for Extract, and this is the first step in any SSIS data flow. SSIS provides a rich set of source components that allow you to connect to and extract data from a wide variety of systems. The 70-463 Exam would have expected you to be familiar with the most common source types. To configure a source, you first need to create a connection manager, which stores the connection string information for the source system.
The most frequently used source is the OLE DB Source. This component is used to extract data from any relational database that has an OLE DB provider, which includes Microsoft SQL Server, Oracle, and many others. You configure the OLE DB Source by specifying the connection manager and then either selecting a table or view, or writing a custom T-SQL query to extract the exact data you need. Writing a specific query is often the best practice, as it allows you to select only the columns and rows you need, which improves performance.
Another very common source is the Flat File Source. This is used to extract data from delimited text files (like CSV files) or fixed-width text files. When you configure a Flat File Source, you need to define the metadata for the file, which includes specifying the column delimiter (e.g., a comma), the row delimiter, and the data type for each column in the file.
SSIS also provides sources for other common data formats, such as an XML Source for reading XML files and an Excel Source for reading Microsoft Excel spreadsheets. The key to working with any source is to ensure that the data types are correctly defined. SSIS is very strict about data types, and incorrect definitions in the source component are a common cause of downstream errors.
The "T" in ETL, Transform, is where the most complex and interesting work happens, and it is a major focus of the 70-463 Exam. The SSIS Data Flow provides a rich palette of transformation components that you can chain together to cleanse, reshape, and enrich your data as it flows from the source to the destination. These transformations are performed in memory, which makes them very high-performance.
One of the most essential transformations is the Lookup. The Lookup transformation is used to join the incoming data from your source with a reference table. Its most common use in a data warehouse ETL is to find the surrogate key for a given business key. For example, as your sales data flows through, you would use a Lookup against the DimProduct table to find the correct ProductSurrogateKey for each ProductBusinessKey in your source data.
The Derived Column transformation is used to create new columns in your data flow. You can use it to perform calculations (e.g., calculating a TotalPrice by multiplying Quantity and UnitPrice), to concatenate strings, or to apply functions to existing columns. The Conditional Split transformation is like a CASE statement for your data flow. It allows you to route rows to different outputs based on a set of conditions. This is often used for data quality checks, for example, to send valid rows to the destination and invalid rows to an error logging table.
Other important transformations include the Data Conversion for changing the data type of a column, the Aggregate for performing GROUP BY operations, and the Merge Join for combining data from two different sources. A typical SSIS data flow will consist of a chain of these components, each performing a specific part of the transformation logic.
The final step in the ETL process is "L" for Load. After the data has been extracted and transformed, it must be loaded into the target tables in your data warehouse. SSIS provides several destination components for this purpose. For the 70-463 Exam, the most important is the OLE DB Destination. This component is used to load data into a table in a relational database like SQL Server.
When you configure the OLE DB Destination, you specify the connection manager for your data warehouse and the target table you want to load. You then need to map the columns from your data flow to the columns in the destination table. The component will automatically match columns with the same name, but you may need to adjust the mappings manually.
A critical setting for performance is the data access mode. The OLE DB Destination supports several modes, but for loading a data warehouse, you will almost always want to use one of the "fast load" options. These options perform a bulk insert operation, which is much faster than inserting the rows one by one. To use fast load, you can also configure settings like the number of rows to commit in a single batch.
Just as with the source components, it is crucial to ensure that the data types of the columns in your data flow exactly match the data types of the columns in your destination table. Any mismatch will cause the load to fail. You often need to use a Data Conversion transformation just before the destination component to ensure that all the data types are correct.
Building an ETL package that works correctly on your development machine is one thing. Building a package that is robust, reliable, and easy to troubleshoot in a production environment is another. The 70-463 Exam would have required you to know how to implement the key features in SSIS for production-level reliability. This includes logging, error handling, and restartability.
SSIS provides a comprehensive logging framework. You can configure your package to log a wide variety of events, such as when the package starts and stops, when a task fails, or when a data flow component processes a certain number of rows. These logs can be written to various destinations, including a text file, the Windows Event Log, or a SQL Server table. Proper logging is essential for auditing and for diagnosing failures after the fact.
For real-time error handling, SSIS uses a mechanism called event handlers. You can create an event handler for a specific event, such as the OnError event of a task. This event handler is like a mini-package that will execute automatically if the error event occurs. For example, you could create an OnError event handler that sends an email notification to the administrator, alerting them that the package has failed.
For long-running packages, you may want to implement checkpoints. Checkpoints allow a package that has failed to be restarted from the point of failure, rather than having to start over from the beginning. You can configure a package to save its state to a checkpoint file at the successful completion of each task. If the package then fails on a subsequent task, you can restart it, and it will read the checkpoint file and resume execution from the failed task.
Moving beyond the core mechanics of ETL, a truly robust data warehouse is not just about moving data; it is about ensuring that the data is accurate, consistent, and trustworthy. The 70-463 Exam recognized this by dedicating a significant portion of its objectives to the advanced topics of data quality and master data management. These disciplines are what elevate a data warehouse from a simple data repository to a reliable foundation for business intelligence. An administrator must be proficient in the tools and techniques used to cleanse data and to manage a single version of the truth.
In this fourth part of our series, we will explore the Microsoft tools designed to tackle these challenges. We will provide an introduction to Data Quality Services (DQS), explaining its role in cleansing and standardizing data through a knowledge-driven approach. We will then shift our focus to Master Data Services (MDS), the platform for establishing an authoritative source for an organization's most critical data entities. We will cover the architecture of both DQS and MDS and discuss how they are integrated into the broader data warehousing and ETL process, all of which are essential concepts for the 70-463 Exam.
The advanced sections of the 70-463 Exam were designed to test a developer's ability to build a complete and enterprise-ready data warehousing solution. This meant moving beyond the basic "extract, transform, load" pattern and into the more nuanced and challenging areas of data governance. The questions in this domain would have focused on your ability to use the specialized tools in the Microsoft BI stack—DQS and MDS—to solve common data integrity problems that plague many organizations.
A key focus would have been on the practical application of Data Quality Services. The exam would have expected you to understand that DQS is not a fully automated tool, but rather a knowledge-driven one. You would need to demonstrate your understanding of how to build a DQS Knowledge Base, which is where you define the rules and valid domains for your data. The exam would then test your ability to use this knowledge base within an SSIS package to cleanse messy source data as it flows into your warehouse.
The exam would also have required a solid conceptual understanding of Master Data Management (MDM) and the role of Master Data Services. You would need to be able to explain why a separate MDM solution is necessary and how it helps to solve the problem of having multiple, conflicting versions of critical data (like customer or product information) scattered across different application silos. The focus would be on the integration of MDS with the data warehouse ETL process.
Ultimately, this section of the 70-463 Exam was about ensuring data trustworthiness. A certified professional must understand that loading garbage data into a data warehouse will only result in garbage analytics. The skills tested here are about implementing the processes and systems needed to ensure that the data loaded into the warehouse is of the highest possible quality, providing a solid and reliable foundation for all subsequent reporting and analysis.
Data Quality Services, or DQS, is a component of the Microsoft SQL Server stack that is designed to help organizations improve the quality of their data. For the 70-463 Exam, a solid understanding of the purpose and basic operation of DQS is essential. DQS is a knowledge-based solution. This means that you, as a data steward or developer, "teach" DQS about your data by creating a Knowledge Base (KB). The KB is the central repository of all the rules, validations, and reference data that DQS will use to cleanse your source data.
The DQS workflow consists of two main activities: knowledge management and data quality projects. Knowledge management is the process of building and maintaining your Knowledge Base. This is done using a tool called the DQS Client. Inside the KB, you create "domains," where each domain represents a specific data field, like "Country" or "State." For each domain, you can define its properties, such as its data type, and you can populate it with a list of valid values, spelling variations, and validation rules.
Once the Knowledge Base is built, you can use it to perform data cleansing. This is done through a data quality project. In a project, you map the columns from your source data to the domains in your Knowledge Base. DQS will then process your source data and compare it against the knowledge in the KB. It will automatically correct spelling mistakes, standardize formatting, and flag any values that are invalid or do not conform to the domain rules.
The real power of DQS in a data warehousing context comes from its integration with SSIS. SSIS provides a special "DQS Cleansing" transformation that allows you to embed this data cleansing process directly into your ETL data flow. This enables you to cleanse your data in real-time as it is being loaded into the data warehouse.
The foundation of any data cleansing operation in DQS is the Knowledge Base (KB). The 70-463 Exam would have expected you to know the conceptual steps involved in creating and populating a KB. The process begins in the DQS Client, where you choose to create a new Knowledge Base. You will give the KB a name and can base it on an existing KB if you wish. The core activity within the KB is domain management.
A domain is the representation of a single data field. For example, if you need to cleanse country data, you would create a "Country" domain. You can then populate this domain with a list of valid values. You can do this manually, by importing them from a table, or by having DQS discover them from a sample data file. Once the values are in the domain, you can manage them, for example, by specifying that "United States" and "USA" are synonyms and that "USA" should be the standard output value.
DQS also allows you to define domain rules. A domain rule is a validation that checks for the logical consistency of the data. For example, in an "Email Address" domain, you could create a rule that states the value must contain an "@" symbol. Any incoming email address that does not meet this rule will be flagged as invalid. This allows you to enforce business logic and data integrity.
A powerful feature of DQS is its ability to use reference data services. You can configure DQS to connect to a cloud-based data service (often provided through the Azure Marketplace). This allows you to validate your data, such as addresses or company names, against a trusted, third-party reference data set. The process of building and enriching the Knowledge Base is an iterative one, and it is the key to achieving high-quality data cleansing.
Go to testing centre with ease on our mind when you use Microsoft MCSA 70-463 vce exam dumps, practice test questions and answers. Microsoft 70-463 MCSA Implementing a Data Warehouse with Microsoft SQL Server 2012/2014 certification practice test questions and answers, study guide, exam dumps and video training course in vce format to help you study with ease. Prepare with confidence and study using Microsoft MCSA 70-463 exam dumps & practice test questions and answers vce from ExamCollection.
Purchase Individually

Microsoft 70-463 Video Course
Top Microsoft Certifications




























































Top Microsoft Certification Exams
Site Search:

SPECIAL OFFER: GET 10% OFF

Pass your Exam with ExamCollection's PREMIUM files!
SPECIAL OFFER: GET 10% OFF
Use Discount Code:
MIN10OFF
A confirmation link was sent to your e-mail.
Please check your mailbox for a message from support@examcollection.com and follow the directions.

Download Free Demo of VCE Exam Simulator
Experience Avanset VCE Exam Simulator for yourself.
Simply submit your e-mail address below to get started with our interactive software demo of your free trial.

here is 70-463 vce which has made my prep easy when used with vce simulator. i am more than happy that i prepared in the shortest time and passed
i have really best prep materials for 70-463. i used them and passed. i am sure that when u use it gonna be a perfect plan for you also. please try to check the uploaded materials
i am not for any material here, i av learnt to always do my 70-463 exam preparation with instructor led training course. i think it is the best way to prepare
let’s make some things straight . 70-463 exam questions are not easy and we need to prepare really good. let’s not think that the questions will be so easy because that perception can make us fail
wow!!! exam 70-463 dumps helped me so much after i revised using them two weeks before the main exam date. never too late to start applying something new if you want to pass.
@nicholas, the best way that i can advise you to do is to go through the best 70-463 exam dumps. also use as many materials as u can so that you get familiar with the most used concepts
here are a lot of important things that we should know in order to excel . let us learn form the professionals who passed Microsoft 70-463. we will be able to discuss the most important concepts together here. kindly invite someone
i am well prepared now. the main exam will be easy because 70-463 Dumps are unique so am now sure that the exam wont be so tough.
i want to pass exam 70-463 but am not quite familiar with the theme. but i really want to learn. can someone guide me a little bit
wow! i have just passed my 70 463 i think i now fully understand all the practical concepts and theory. go ahead it wont be so tough for you