


Premium File
798 Q&A
$76.99$69.99
CompTIA Server+ SK0-004 Exam Questions & Answers, Accurate & Verified By IT Experts
Instant Download, Free Fast Updates, 99.6% Pass Rate
798 Questions & Answers
Last Update: Jul 17, 2026
$69.99
CompTIA Server+ SK0-004 Exam Screenshots
CompTIA Server+ SK0-004 Practice Test Questions in VCE Format
| File | Votes | Size | Date |
|---|---|---|---|
File CompTIA.Pass4sureexam.SK0-004.v2019-08-15.by.Blain.305q.vce |
Votes 7 |
Size 322 KB |
Date Aug 18, 2019 |
File CompTIA.BrainDumps.SK0-004.v2016-03-01.by.Joev.182q.vce |
Votes 37 |
Size 101.57 KB |
Date Mar 01, 2016 |
CompTIA Server+ SK0-004 Practice Test Questions, Exam Dumps
CompTIA SK0-004 (CompTIA Server+) exam dumps vce, practice test questions, study guide & video training course to study and pass quickly and easily. CompTIA SK0-004 CompTIA Server+ exam dumps & practice test questions and answers. You need avanset vce exam simulator in order to study the CompTIA Server+ SK0-004 certification exam dumps & CompTIA Server+ SK0-004 practice test questions in vce format.
The CompTIA Server+ SK0-004 certification is a globally recognized credential that validates the skills required of server administrators. It signifies that a professional possesses the knowledge to build, maintain, troubleshoot, secure, and support server hardware and software technologies. The SK0-004 exam covers a broad range of topics, including virtualization, storage, security, and networking, reflecting the complex and evolving nature of modern IT environments. Earning this certification demonstrates a professional's competency in handling the physical and virtual aspects of server management, which is a critical function for any organization that relies on data and networked services.
Server architecture forms the foundational blueprint of an organization's IT infrastructure. Understanding the different form factors is crucial for planning and deployment. Tower servers resemble a standard desktop computer and are often used in small businesses due to their simplicity and lower initial cost. Rack servers, on the other hand, are designed to be mounted in a server rack, allowing for high-density deployments in data centers. They are ideal for medium to large enterprises that require scalability. Blade servers represent the most compact form factor, where multiple server modules, or blades, are housed in a single chassis, sharing power and cooling resources. This design maximizes space and energy efficiency for large-scale operations.
The internal components of a server are engineered for performance, reliability, and continuous operation, differentiating them from standard desktop hardware. Server motherboards, for instance, often feature multiple CPU sockets to support multi-processor configurations, providing immense processing power for demanding applications. They also include more memory slots to accommodate larger amounts of RAM, which is essential for virtualization and database management. The choice of CPU, such as those from the Intel Xeon or AMD EPYC lines, is critical as they offer features like more cores, larger cache sizes, and support for Error-Correcting Code (ECC) memory, which are vital for server stability and performance.
The process of installing and configuring server hardware requires meticulous attention to detail to ensure system stability and performance. When installing a central processing unit (CPU), it is essential to handle the component carefully to avoid damaging the sensitive pins on the processor or the motherboard socket. Applying the correct amount of thermal paste between the CPU and the heat sink is critical for effective heat dissipation, preventing the processor from overheating under load. Following the manufacturer's guidelines for torque and installation sequence for the heat sink ensures proper contact and thermal transfer, which is a key aspect of the SK0-004 curriculum.
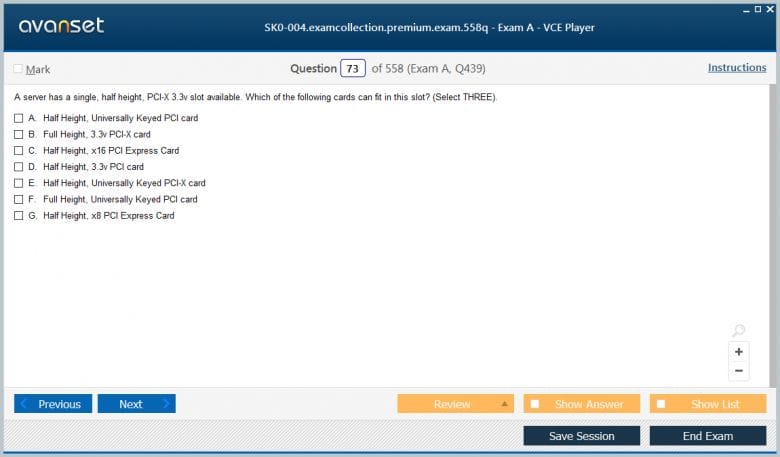
Memory installation is another critical step. Servers utilize specific types of RAM, such as ECC memory, which can detect and correct common kinds of internal data corruption. It is important to install memory modules in the correct slots and configurations to enable features like multi-channel architecture, which increases memory bandwidth. Technicians must consult the server motherboard's manual to understand the proper population order. Similarly, installing expansion cards like network interface cards (NICs), host bus adapters (HBAs), or RAID controllers requires placing them in the appropriate PCIe slots and ensuring that the necessary drivers are installed in the operating system for proper functionality.
Effective power management is a cornerstone of server reliability, a topic heavily emphasized in the SK0-004 exam. Servers in business-critical environments are almost always equipped with redundant power supply units (PSUs). This configuration ensures that if one PSU fails, the other can immediately take over the full load without any interruption to the server's operation. This feature, known as N+1 redundancy, is fundamental to achieving high availability. Furthermore, these PSUs are often hot-swappable, allowing a failed unit to be replaced without shutting down the server, thus minimizing downtime and maintaining continuous service delivery for the organization.
An Uninterruptible Power Supply (UPS) provides emergency power to a server in the event of a main power failure. It contains a battery that kicks in instantly, giving the server enough time for a graceful shutdown or for a backup generator to start. This prevents data corruption and hardware damage that can result from a sudden loss of power. For larger data centers, sophisticated power distribution units (PDUs) are used to manage and monitor power consumption at the rack level. These PDUs can provide detailed analytics on power usage, helping administrators optimize energy efficiency and balance power loads across the infrastructure.
Cooling is just as critical as power for server health and longevity. Servers generate a significant amount of heat, and if not managed properly, high temperatures can lead to component failure and reduced performance. Data centers employ advanced heating, ventilation, and air conditioning (HVAC) systems to maintain a stable operating temperature and humidity. A common data center cooling strategy is the hot aisle/cold aisle layout. In this configuration, server racks are arranged in rows, with cold air intake aisles and hot air exhaust aisles. This prevents hot exhaust air from recirculating back into server intakes, dramatically improving cooling efficiency.
Redundant Array of Independent Disks (RAID) is a storage technology that combines multiple physical disk drives into a single logical unit for the purposes of data redundancy, performance improvement, or both. Understanding RAID is essential for any server administrator and is a key domain in the SK0-004 exam. RAID levels offer different balances of protection, capacity, and speed. For instance, RAID 0 (striping) writes data across multiple drives, which significantly boosts performance but offers no redundancy. If one drive fails in a RAID 0 array, all data on the array is lost, making it suitable for non-critical, high-performance tasks.
For data protection, RAID 1 (mirroring) is a common choice. It writes identical data to two or more drives, creating a mirror image. If one drive fails, the other can continue to operate without any data loss. This provides excellent redundancy but at the cost of storage efficiency, as the total usable capacity is only that of a single drive. RAID 5 combines striping with parity, distributing parity information across all drives. This level provides a good balance of performance and redundancy, as it can withstand the failure of one drive. It is a cost-effective solution for many business applications.
RAID 6 is similar to RAID 5 but uses double parity, allowing it to tolerate the failure of up to two drives simultaneously. This makes it ideal for large arrays where the probability of multiple drive failures during a rebuild is higher. RAID 10 (or RAID 1+0) is a nested RAID level that combines the mirroring of RAID 1 with the striping of RAID 0. It offers high performance and high redundancy but is more expensive as it requires a minimum of four drives and utilizes only half of the total drive capacity. Configuring these RAID levels can be done through a dedicated hardware RAID controller or through software within the operating system.
Beyond the internal drives configured in a RAID array, servers connect to various storage technologies to meet different capacity and performance needs. Direct Attached Storage (DAS) is the most straightforward model, where storage devices are connected directly to a single server, typically via SAS (Serial Attached SCSI) or SATA (Serial ATA) interfaces. While simple and high-performing, DAS is not easily shared with other servers, which can limit its scalability and flexibility. It is often the storage model used for a server's internal boot drives and local application data, and its fundamentals are part of the SK0-004 objectives.
Network Attached Storage (NAS) provides a more flexible solution. A NAS is a dedicated file-level storage device connected to a network, allowing multiple users and servers to access data from a central location. It uses network protocols like SMB/CIFS (for Windows environments) or NFS (for Linux/Unix environments) to share files. NAS devices are relatively easy to set up and manage, making them a popular choice for centralized file storage, backups, and data archiving in small to medium-sized businesses. They abstract the file system management away from the client servers.
For high-performance, block-level storage in enterprise environments, a Storage Area Network (SAN) is often deployed. A SAN is a dedicated, high-speed network that interconnects servers with storage arrays. Unlike NAS, a SAN provides block-level access to storage, meaning it appears to the server's operating system as a locally attached drive. This makes it suitable for demanding applications like databases and virtualization. SANs typically use protocols like Fibre Channel (FC) or iSCSI (Internet Small Computer System Interface) to transport storage traffic, offering low latency and high throughput for mission-critical workloads.
A solid understanding of networking principles is non-negotiable for a server administrator preparing for the SK0-004 exam. At the core of server communication is the Internet Protocol (IP) addressing system. Servers must be configured with a static IP address, either IPv4 or IPv6, to ensure that they are consistently reachable on the network. Unlike client machines that can use dynamic addresses assigned by DHCP, a server's address must remain constant so that other devices and services can reliably connect to it. Proper subnetting is also crucial for segmenting networks, improving security, and managing traffic efficiently within a large IT environment.
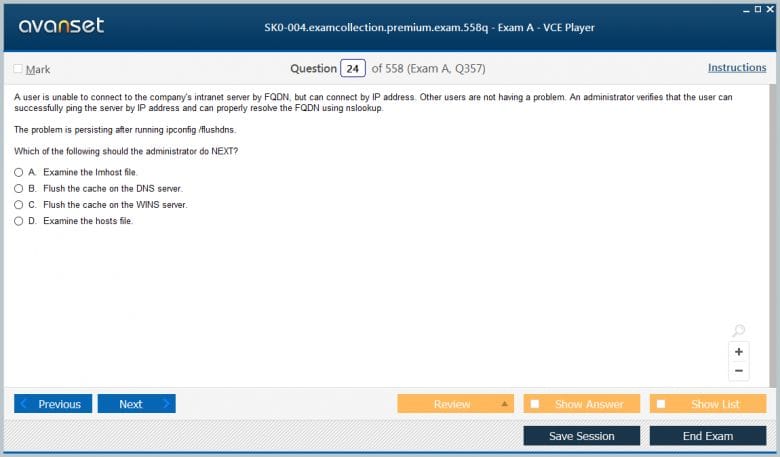
Domain Name System (DNS) is another critical network service that server administrators must manage. DNS translates human-readable domain names, like a company website, into machine-readable IP addresses. Servers often host DNS zones for an organization's domain, managing records such as A records (for hostname to IPv4), AAAA records (for hostname to IPv6), MX records (for mail exchange), and CNAME records (for aliases). A misconfigured DNS server can render network services inaccessible, highlighting its importance in the overall infrastructure and its prominence in SK0-004 topics.
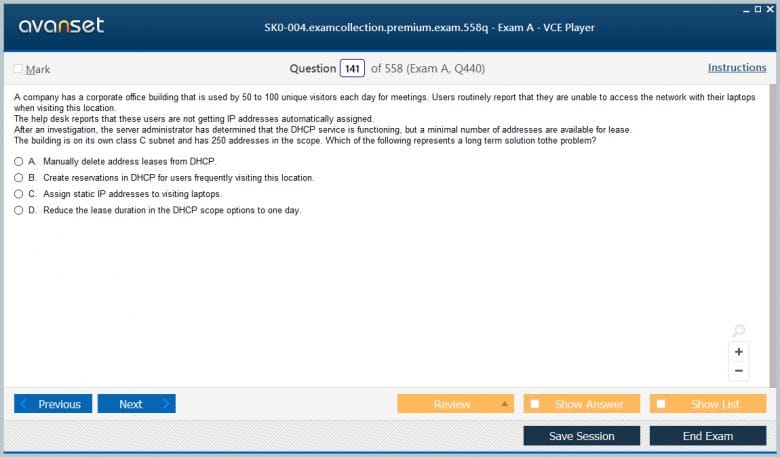
Dynamic Host Configuration Protocol (DHCP) is a network management protocol used to automate the process of assigning IP addresses and other network configuration parameters to devices on a network. While servers themselves should have static IP addresses, they are often configured to run the DHCP service for client workstations, printers, and other network devices. The server administrator is responsible for configuring DHCP scopes, which are ranges of IP addresses available for assignment, and setting options like the default gateway, DNS server addresses, and lease durations to ensure the smooth operation of the client network.
Effective server administration is the core responsibility of any IT professional working with infrastructure, and it forms a significant portion of the CompTIA Server+ SK0-004 exam objectives. This involves not just the initial setup but the ongoing management of the server operating system, its roles, and the services it provides. A server administrator must be proficient in a variety of tasks, from installing and configuring operating systems to managing users and groups, and from leveraging the command line for efficiency to embracing virtualization for scalability and resource optimization. This part delves into these critical administrative functions that are essential for maintaining a stable and efficient server environment.
The foundation of any server is its operating system (OS). The installation and initial configuration of a server OS is a detailed process that requires careful planning. Two major families of server operating systems dominate the market: Microsoft Windows Server and various distributions of Linux, such as Red Hat Enterprise Linux, CentOS, or Ubuntu Server. The choice of OS often depends on the specific applications and services the server will host. For example, a server intended to run Microsoft SQL Server or Active Directory would require Windows Server, while a web server running the LAMP stack (Linux, Apache, MySQL, PHP) would use a Linux distribution.
The installation process typically begins with booting the server from installation media, which could be a USB drive, a DVD, or a network-based deployment server. During the setup, the administrator must make several critical decisions. This includes partitioning the storage drives, which involves deciding on the layout and size of the partitions for the OS, applications, and data. Choosing the correct file system, such as NTFS for Windows or ext4 or XFS for Linux, is also a key step. After the base OS is installed, initial configuration tasks include setting the server name, configuring the network interface with a static IP address, and setting the correct time zone.
Furthermore, post-installation tasks are crucial for securing and preparing the server for its role. This includes performing all initial system updates to patch any security vulnerabilities and install the latest drivers. It is also a best practice to configure the server's local firewall to allow only necessary traffic. For Windows Server, administrators may choose between the full Desktop Experience, which provides a graphical user interface (GUI), or Server Core, which is a minimal installation managed primarily through the command line. Server Core has a smaller attack surface and uses fewer system resources, making it a more secure and efficient choice for specific roles.
Once a server operating system is installed and configured, its primary purpose is to provide services to the network through specific roles and features. A server role is a primary function that the server performs, such as a file server, a web server, or a DNS server. A feature, on the other hand, is a smaller program or service that supports the server's functionality but is not its main purpose. In Windows Server, roles and features are added and managed through the Server Manager console or via PowerShell, which is a key skill for the SK0-004 certification.
A common and fundamental role is that of a file server, which provides a central location for storing and sharing files. Administrators configure shared folders, set permissions to control access, and can implement features like quotas to limit the amount of storage space a user can consume. Another prevalent role is that of a web server. Using software like Microsoft's Internet Information Services (IIS) or the open-source Apache or Nginx on Linux, a server can host websites and web applications. Configuration involves setting up website bindings, managing SSL certificates for secure connections, and configuring application pools for performance.
Print servers centralize the management of printers on a network. Instead of connecting printers to individual workstations, they are connected to the network and managed by the print server. This allows administrators to deploy printers to users and groups through policies and manage print queues and drivers from a single location. An application server is a more specialized role designed to run specific business applications, such as a database server running SQL or a messaging server running Microsoft Exchange. Properly configuring and maintaining these roles is essential for delivering reliable IT services to the organization.
Managing user and group accounts is a fundamental task in server administration, critical for maintaining security and controlling access to resources. Every user who needs to access network resources must have a user account. This account authenticates their identity and is associated with a set of privileges that determine what they are allowed to do. Administrators are responsible for the entire lifecycle of a user account, from creation to modification to eventual deletion when an employee leaves the organization. Best practices include enforcing strong password policies, such as requirements for length, complexity, and regular changes.
Groups are collections of user accounts that simplify administration. Instead of assigning permissions to individual users one by one, an administrator can assign permissions to a group. Any user who is a member of that group automatically inherits its permissions. This model is far more efficient and less prone to error. For example, a group called "Accounting" could be given access to the finance department's shared folder. When a new employee joins the accounting team, the administrator simply adds their user account to this group, and they instantly have all the necessary access rights.
In a Windows Server environment using Active Directory, user and group management is often structured using Organizational Units (OUs). OUs are containers within a domain that can hold users, groups, computers, and other OUs. This allows for a hierarchical structure that can mirror an organization's departmental or geographical layout. Administrators can then apply specific policies, known as Group Policy Objects (GPOs), to an entire OU. This powerful feature enables the centralized management of settings and security configurations for large numbers of users and computers, a key concept for anyone preparing for the SK0-004 exam.
While graphical user interfaces (GUIs) are user-friendly, the command-line interface (CLI) remains an indispensable tool for server administrators seeking efficiency, automation, and powerful control. The CLI allows administrators to perform complex tasks with a single command, script repetitive actions, and manage servers remotely in low-bandwidth situations. For Windows Server, the traditional Command Prompt is still available, but PowerShell has become the standard for modern administration. PowerShell is an object-oriented scripting language that provides comprehensive control over all aspects of the Windows Server OS and its roles.
Linux server administration has always been heavily reliant on the CLI. The bash shell is the most common interface, and administrators use a vast array of commands to manage the system. Commands like ls to list files, cp to copy, mv to move, grep to search text, and chmod to change permissions are fundamental. System management tasks such as checking service status with systemctl, managing network interfaces with ip or ifconfig, and monitoring system resources with top or htop are all performed from the command line. The ability to pipe the output of one command into another allows for the creation of powerful command chains to process data efficiently.
Proficiency with the CLI is a critical skill tested by the SK0-004 exam because it is essential for automation. Administrators can write scripts in PowerShell or bash to automate routine tasks such as creating user accounts, backing up data, or applying updates across multiple servers. This not only saves a significant amount of time but also ensures consistency and reduces the potential for human error. For managing servers in a cloud or virtualized environment, where many servers may need to be configured identically, scripting and CLI tools are not just a convenience but a necessity for effective management.
Server virtualization is a technology that allows a single physical server to run multiple independent virtual machines (VMs). This has revolutionized the data center by dramatically improving hardware utilization, reducing costs, and increasing flexibility. The core component of virtualization is the hypervisor, which is a layer of software that sits between the physical hardware and the virtual machines. The hypervisor is responsible for abstracting the server's physical resources—such as CPU, memory, and storage—and allocating them to each VM. The SK0-004 exam places a strong emphasis on understanding these core concepts.
There are two main types of hypervisors. A Type 1 hypervisor, also known as a bare-metal hypervisor, runs directly on the host's hardware. Examples include VMware ESXi, Microsoft Hyper-V, and the open-source KVM. Because they have direct access to the hardware, Type 1 hypervisors are extremely efficient and provide the best performance, making them the standard for enterprise data centers. A Type 2 hypervisor, or hosted hypervisor, runs as an application on top of a conventional operating system. Examples include VMware Workstation and Oracle VirtualBox. These are typically used for desktop and development purposes rather than for production server workloads.
Virtualization offers numerous benefits. It leads to significant server consolidation, meaning fewer physical servers are needed, which reduces costs associated with hardware, power, and cooling. It also provides greater agility. A new virtual server can be provisioned in minutes, whereas deploying a new physical server could take days or weeks. Virtualization is also a key enabler for disaster recovery. Entire VMs can be replicated to a secondary site, allowing for rapid failover in the event of an outage. The process of converting a physical server into a virtual machine, known as a Physical-to-Virtual (P2V) migration, is a common task used to transition legacy infrastructure into a modern virtualized environment.
Once a hypervisor is in place, the primary task for an administrator is the creation and management of virtual machines (VMs). Creating a VM involves defining its virtual hardware configuration. This includes specifying the number of virtual CPUs (vCPUs), the amount of RAM, the size of the virtual hard disks, and the number of virtual network interface cards (vNICs) it will have. These resources are allocated from the physical host's resource pools. It is crucial for administrators to carefully plan this allocation to avoid overprovisioning, which can lead to performance degradation for all VMs running on the host.
Day-to-day management of VMs involves a variety of tasks covered in the SK0-004 objectives. Administrators regularly monitor the performance of VMs to ensure they have adequate resources. If a VM is consistently running low on memory or high on CPU usage, its allocated resources can often be adjusted dynamically. Another powerful feature of virtualization is the ability to take snapshots. A snapshot captures the entire state of a VM—including its memory, settings, and disk state—at a specific point in time. This is incredibly useful before performing risky operations like software updates or configuration changes, as it allows the administrator to quickly revert the VM to its previous state if something goes wrong.
Cloning and templating are features that streamline the deployment of new VMs. A clone is an exact copy of an existing VM. A template is a master copy of a VM that is used as a blueprint for creating new, pre-configured VMs. By creating a template with the operating system installed, updated, and hardened, an administrator can rapidly deploy new servers that are consistent and adhere to company standards. Managing the lifecycle of VMs, from creation and operation to eventual decommissioning, is a continuous process that requires a strong understanding of the virtualization platform's management tools, whether it be VMware vCenter, Microsoft System Center Virtual Machine Manager, or others.
In modern server environments, storage and security are two pillars that support the entire IT infrastructure. The CompTIA Server+ SK0-004 certification places a heavy emphasis on these domains, as the integrity and availability of data are paramount to any organization. Proper management of advanced storage solutions ensures that data is accessible, scalable, and performs well under load. Simultaneously, robust security practices are required to protect that data and the servers that host it from a constantly evolving landscape of threats. This part will explore the advanced storage solutions and fundamental security principles that every server administrator must master.
While direct-attached storage (DAS) serves basic needs, enterprise environments require more scalable and flexible solutions like Network Attached Storage (NAS) and Storage Area Networks (SAN). A NAS is essentially a dedicated file server that provides file-level storage over a standard Ethernet network. It is simple to manage and ideal for centralizing unstructured data like documents, spreadsheets, and media files. NAS devices use common network file-sharing protocols, primarily Server Message Block (SMB) for Windows clients and Network File System (NFS) for Linux and Unix clients. This makes them easily accessible to a wide range of devices on the network.
A Storage Area Network (SAN), in contrast, provides block-level storage over a dedicated, high-speed network. This means that to the server's operating system, the SAN storage appears as if it were a locally attached disk drive. This low-level access makes SANs the preferred choice for performance-sensitive and mission-critical applications such as large databases and high-density virtualization clusters. The underlying network for a SAN is traditionally built on Fibre Channel (FC), a technology known for its high speed and reliability. However, iSCSI (Internet Small Computer System Interface) has become a popular alternative, as it allows block-level storage traffic to be transmitted over standard Ethernet networks, reducing cost and complexity.
Choosing between NAS and SAN depends entirely on the workload requirements, a key decision point for SK0-004 professionals. NAS is excellent for file sharing and consolidation due to its ease of use and cost-effectiveness. SAN is the superior choice for applications that require high throughput and low latency, offering performance that is comparable to local storage. In many large organizations, a hybrid approach is used, leveraging both technologies for what they do best. NAS systems handle general file services and backups, while SANs provide the storage backbone for critical enterprise applications and virtual machine datastores.
The core principles of information security are often summarized by the CIA triad: Confidentiality, Integrity, and Availability. Confidentiality ensures that data is accessible only to authorized individuals. This is achieved through mechanisms like encryption and access control lists. Integrity means that data is accurate and trustworthy, and that it has not been altered in an unauthorized manner. Technologies like hashing algorithms and digital signatures are used to verify data integrity. Availability ensures that systems and data are accessible to authorized users when they need them. This is achieved through redundancy, backups, and disaster recovery planning.
Physical security is the first line of defense in protecting server infrastructure. Data centers and server rooms must be physically secured to prevent unauthorized access, theft, or damage. This includes measures such as locked doors, electronic access control systems using key cards or biometric scanners, and video surveillance. Environmental controls are also a component of physical security. Maintaining proper temperature and humidity levels, along with implementing fire suppression systems, is crucial to protect the hardware from physical damage. The SK0-004 exam expects administrators to be familiar with these foundational security measures that protect the physical assets.
Beyond the physical realm, logical security measures are implemented within the software and network to protect data. This involves creating a defense-in-depth strategy, where multiple layers of security controls are implemented. If one layer is breached, others are still in place to protect the assets. This multi-layered approach includes firewalls at the network perimeter, intrusion detection systems, antivirus software on the servers, and strong access control policies. A comprehensive security posture requires a holistic view that combines physical and logical controls to create a resilient and secure environment for the organization's critical systems.
Server hardening is the process of reducing the security vulnerabilities of a server. A primary goal of hardening is to minimize the attack surface, which refers to the sum of all the different points where an unauthorized user could try to enter or extract data. One of the most effective ways to reduce the attack surface is to disable or uninstall any unnecessary services, applications, and network protocols. Every service that is running is a potential entry point for an attacker, so if a service is not required for the server's specific role, it should be turned off. This follows the principle of least functionality.
Configuring a host-based firewall is another critical step in server hardening. Both Windows and Linux include built-in firewalls that can be configured to control inbound and outbound network traffic. The firewall should be set to a default-deny policy, meaning that all traffic is blocked unless it is explicitly allowed. Only the ports required for the server's specific applications and management services should be opened. For example, a web server would need to allow inbound traffic on ports 80 (HTTP) and 443 (HTTPS), but it likely would not need to allow traffic for services like FTP or Telnet.
Applying security baselines is a systematic way to ensure that servers are configured consistently and securely. Organizations often use established security benchmarks from sources like the Center for Internet Security (CIS) or the Defense Information Systems Agency (DISA) as a guide. These baselines provide detailed configuration guidelines for various operating systems and applications. Following these guidelines helps to close common security holes related to user account policies, system permissions, and logging configurations. Regularly auditing servers against these baselines is an important part of maintaining a secure state, a key competency for a SK0-004 certified professional.
Access control is the process of granting or denying specific requests to obtain and use information and related information processing services. It is a fundamental security mechanism that ensures users can only access the resources they are authorized to use. The principle of least privilege is a core concept in access control. It dictates that a user should be given only the minimum levels of access, or permissions, needed to perform their job functions. This minimizes the potential damage that could be caused by a compromised account or a malicious insider.
Authentication is the process of verifying the identity of a user or device. The most common form of authentication is a password, but this method alone is often considered weak. To enhance security, multi-factor authentication (MFA) is widely implemented. MFA requires a user to provide two or more different types of verification before being granted access. These factors are typically categorized as something you know (like a password or PIN), something you have (like a physical token or a smartphone app), or something you are (like a fingerprint or facial scan). MFA significantly increases the difficulty for an attacker to compromise an account.
Authorization occurs after a user has been successfully authenticated. It is the process of determining what an authenticated user is allowed to do. This is typically managed through permissions and access control lists (ACLs). An ACL is a table that tells a computer operating system which access rights each user has to a particular system object, such as a file directory or individual file. Administrators meticulously configure these permissions to enforce the principle of least privilege, ensuring that users in the sales department, for example, cannot access sensitive files belonging to the human resources department.
To protect data as it travels across the network, server administrators rely on a variety of network security protocols. Secure Sockets Layer (SSL) and its more modern and secure successor, Transport Layer Security (TLS), are cryptographic protocols designed to provide secure communication over a computer network. TLS is essential for securing web traffic (HTTPS), email, and many other applications. When a user connects to a secure website, TLS encrypts the data exchanged between the user's browser and the web server, preventing eavesdroppers from intercepting sensitive information like login credentials or credit card numbers.
For secure remote administration of servers, especially Linux servers, Secure Shell (SSH) is the standard protocol. SSH provides a secure, encrypted channel over an unsecured network, allowing an administrator to log in and execute commands on a remote server safely. It replaces older, insecure protocols like Telnet, which transmitted all data, including passwords, in plain text. Using key-based authentication with SSH, where a user has a private key and the server has a corresponding public key, offers even stronger security than using passwords alone. This is a vital tool for any administrator managing servers.
A Virtual Private Network (VPN) creates a secure, encrypted connection, or "tunnel," over a public network like the internet. VPNs are commonly used to allow remote employees to securely connect to the corporate network as if they were physically present in the office. They are also used to securely connect different office locations, creating a wide area network (WAN) over the internet. By encapsulating and encrypting all traffic within the VPN tunnel, these protocols ensure the confidentiality and integrity of data as it traverses the untrusted public network, a critical security function covered in the SK0-004 exam.
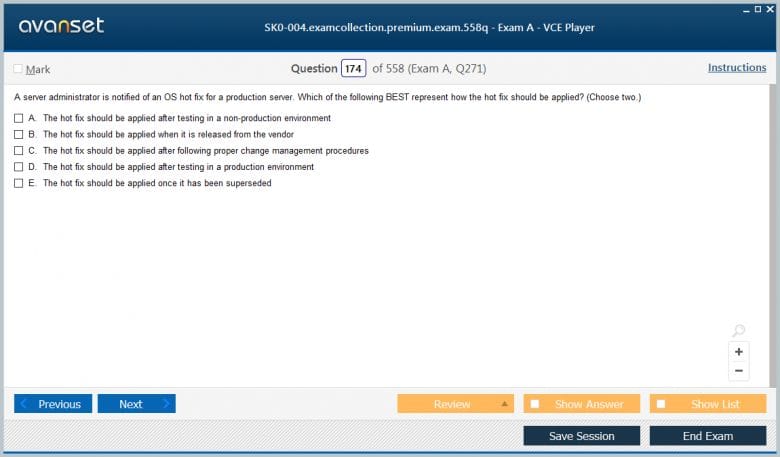
One of the most critical, yet sometimes overlooked, aspects of server security is patch management. Software vendors regularly release patches and updates to fix security vulnerabilities that have been discovered in their products. Applying these patches in a timely manner is essential to protect servers from known exploits. Attackers often scan networks for unpatched systems, and a single vulnerable server can become an entry point for a breach that compromises the entire network. A comprehensive patch management strategy is therefore a non-negotiable part of server administration.
A successful patch management process involves several stages. First, administrators must maintain an accurate inventory of all servers and the software running on them. They then need to monitor for the release of new patches from vendors. Once a patch is released, it should be tested in a non-production environment to ensure that it does not cause any compatibility issues or unintended side effects with existing applications. After successful testing, the patch can be scheduled for deployment to the production servers. This deployment is often done during scheduled maintenance windows to minimize disruption to business operations.
To manage this process at scale, organizations use dedicated patch management tools. In a Windows environment, Windows Server Update Services (WSUS) allows administrators to manage the distribution of updates to all the computers in their network. For larger or more diverse environments, more advanced solutions like Microsoft Endpoint Configuration Manager or third-party tools can provide more granular control, reporting, and automation. Regardless of the tools used, having a formal, documented patch management policy and procedure is a hallmark of a mature security program and a key skill for a server administrator.
The ability to configure, manage, and troubleshoot server networking is a core competency for any server administrator. Servers are the heart of the network, providing critical services, and their connectivity is paramount. Furthermore, when issues arise, a systematic and logical approach to troubleshooting is essential to minimize downtime and resolve problems efficiently. The CompTIA Server+ SK0-004 exam validates that a professional has mastered these skills, from advanced network configurations and remote management to performance monitoring and a methodical troubleshooting process for hardware, software, and network issues. This part explores these vital areas of server management.
Beyond basic IP addressing, server administrators often implement advanced network configurations to enhance performance, reliability, and security. NIC Teaming, also known as link aggregation or bonding, is a common technique where multiple network interface cards (NICs) are combined into a single logical interface. This can be configured in two primary modes. In a load-balancing mode, traffic is distributed across all the NICs in the team, which increases the total available bandwidth to the server. In a failover mode, one NIC is active while the others are on standby, ready to take over instantly if the primary link fails, thus providing network redundancy.
Virtual LANs (VLANs) are used to segment a physical network into multiple logical broadcast domains. This is a crucial security and traffic management technique covered in the SK0-004 curriculum. For example, a server might have virtual machines belonging to different departments, such as finance and marketing. By using VLANs, the network traffic for each department can be isolated, even though the VMs are running on the same physical host. This prevents users in one department from accessing resources in another and helps to contain the spread of network issues. Server NICs and virtual switches must be configured with the correct VLAN tags to participate in these segmented networks.
With the exhaustion of the IPv4 address space, proficiency in IPv6 is becoming increasingly important for server administrators. IPv6 offers a vastly larger address space and includes features like simplified address auto-configuration. Administrators must know how to configure IPv6 addresses on servers, understand the different types of IPv6 addresses (such as global unicast, unique local, and link-local), and be familiar with how IPv6 coexists with IPv4 in a dual-stack environment. Properly configuring both IPv4 and IPv6 ensures that the server can communicate with the full range of devices on modern networks.
Managing servers remotely is a standard practice, allowing administrators to control and maintain servers located in a data center from anywhere in the world. For Windows servers, the Remote Desktop Protocol (RDP) is the primary tool for remote graphical access. RDP allows an administrator to see the server's desktop and interact with it as if they were sitting in front of it. For security, it is critical to use strong passwords and, ideally, configure RDP to run over a secure connection, often protected by a VPN or a Remote Desktop Gateway to avoid exposing the RDP port directly to the internet.
For command-line access, especially on Linux servers, Secure Shell (SSH) is the universal standard. SSH provides an encrypted channel for remote shell access, secure file transfers (using SCP or SFTP), and port forwarding. As discussed in the security section, using key-based authentication instead of passwords with SSH provides a much higher level of security. Many management tasks on both Windows (via PowerShell Remoting) and Linux can be performed efficiently and securely over the command line, which is often faster and more scriptable than using a graphical interface, aligning with skills tested in the SK0-004 exam.
Out-of-band management (OOBM) provides a way to access and manage a server even if its operating system is down or the primary network connection has failed. This is typically achieved through a dedicated management card built into the server, such as Dell's iDRAC (Integrated Dell Remote Access Controller) or HPE's iLO (Integrated Lights-Out). These cards have their own network connection and processor and allow administrators to perform tasks like powering the server on or off, monitoring hardware health, and even accessing a remote console to see the server's screen from the moment it starts booting. OOBM is an essential tool for "lights-out" data center management.
Proactive monitoring of server health and performance is critical for preventing outages and ensuring that services run smoothly. Administrators must keep a close watch on several key performance metrics. CPU utilization indicates how busy the processor is. Consistently high CPU usage might suggest that the server is underpowered for its workload or that a specific process is misbehaving. Memory utilization is another key metric. If a server is constantly using all of its available RAM, it may resort to using slower disk-based virtual memory (paging or swapping), which can severely degrade performance.
Disk I/O (Input/Output) performance is crucial for applications that read and write a lot of data, such as databases. Metrics like disk queue length, latency, and throughput can indicate if the storage system is a bottleneck. Similarly, monitoring network traffic, including bandwidth utilization and the number of errors or dropped packets, can help identify network performance issues. Keeping an eye on these four fundamental resources—CPU, memory, disk, and network—provides a comprehensive view of a server's health. The SK0-004 exam expects candidates to be familiar with these key metrics.
To track these metrics, administrators use a variety of monitoring tools. Operating systems have built-in utilities like Performance Monitor (PerfMon) in Windows and tools like top, htop, and iostat in Linux. These are useful for real-time analysis. For long-term monitoring and alerting, more sophisticated enterprise-grade solutions are used. Tools like Nagios, Zabbix, or Prometheus can collect performance data from hundreds of servers, store it in a database, and generate graphs to visualize trends over time. These systems can also be configured to send automatic alerts to administrators when a metric crosses a predefined threshold, enabling them to address potential issues before they impact users.
When a server issue occurs, a chaotic, haphazard approach can make the problem worse. A systematic troubleshooting methodology is essential for resolving issues quickly and effectively. The first step is always to identify the problem. This involves gathering information from users, log files, and monitoring systems to clearly define the symptoms. It is important to determine the scope of the problem: does it affect one user or many? Is it one application or the entire server? When did the problem start? Having a clear problem definition prevents wasted effort.
Once the problem is identified, the next step is to establish a theory of probable cause. Based on the symptoms and their knowledge of the system, the administrator should form a hypothesis about what might be wrong. This could be anything from a failed hardware component to a recent software update or a network misconfiguration. It is often helpful to start with the most likely or simplest potential causes first. This step is about educated guessing, and a key skill for any SK0-004 certified professional is to make these guesses as educated as possible.
After forming a theory, the administrator must test it to determine if it is correct. This might involve checking a configuration setting, restarting a service, or swapping a suspected faulty component with a known good one. If the test confirms the theory, the administrator can then establish a plan of action to resolve the problem and implement the solution. If the test disproves the theory, the process loops back: the administrator must establish a new theory and test it. This iterative process continues until the root cause is found. Finally, after resolving the issue, it is crucial to verify full system functionality and document the findings, actions, and outcomes to prevent future occurrences.
Server hardware issues can often be daunting, but a logical approach can simplify the process. Many problems are identified during the server's startup sequence, known as the Power-On Self-Test (POST). During POST, the server's firmware checks the essential hardware components. If an error is detected, the server may emit a series of audible beep codes or display an error message on the console. Administrators must know how to interpret these codes by consulting the server manufacturer's documentation to pinpoint the faulty component, which could be the CPU, RAM, or another critical part.
Memory problems are a frequent cause of server instability, leading to unexpected reboots or system crashes (blue screens in Windows or kernel panics in Linux). If a RAM module is suspected to be faulty, the administrator can test it using diagnostic tools like MemTest86+. It is also good practice to reseat the memory modules, as they can sometimes become loose. If the server has multiple modules, the administrator can try removing them one by one to isolate the specific faulty stick. Ensuring that the RAM installed is the correct type (e.g., ECC) and speed for the motherboard is also a critical check.
Storage system issues can manifest as slow performance, data corruption, or failure to boot the operating system. The first step is to check the physical connections of the drives. For RAID arrays, the RAID controller's management utility is the primary tool for diagnosis. This utility will report the status of the array and each individual drive. If a drive has failed in a redundant array (like RAID 1, 5, or 6), the administrator can hot-swap the failed drive with a new one, and the array will begin the rebuilding process. Power supply issues are often indicated by a server that fails to power on at all or shuts down unexpectedly. Testing with a known good power supply is the definitive way to diagnose a faulty PSU.
When the hardware seems fine, the problem may lie within the operating system or the applications running on it. An OS that fails to boot can be a complex issue. The troubleshooting process might involve booting into a recovery mode or using an installation disk to access repair tools. Common tools like bootrec in Windows or grub-install in Linux can be used to repair the master boot record or bootloader. Reviewing boot logs can also provide clues as to where in the startup process the failure is occurring.
Service failures are another common software issue. If a critical service, like a web server or database service, fails to start, it can render an application unusable. The first place to look for clues is the system's event logs. In Windows, the Event Viewer provides detailed logs categorized by application, security, and system. In Linux, logs are typically found in the /var/log directory, with journalctl being the modern tool for querying the systemd journal. These logs will often contain error messages that point directly to the cause of the service failure, such as a missing dependency or a configuration error.
Performance degradation, where the server becomes slow and unresponsive, requires a different approach. The administrator should use performance monitoring tools to identify the resource bottleneck. Is the CPU constantly at 100%? Is the system running out of memory and swapping heavily to disk? Is a particular process consuming an excessive amount of resources? Once the bottleneck is identified, the administrator can take corrective action. This might involve optimizing an application's configuration, adding more physical resources to the server, or terminating a runaway process. This type of analytical skill is a key part of the SK0-004 skillset.
The final domains of server administration, and crucial components of the CompTIA Server+ SK0-004 exam, revolve around ensuring business continuity and maintaining an orderly operational environment. This includes robust backup and recovery strategies, comprehensive disaster recovery planning, and the implementation of high-availability solutions to minimize downtime. It also encompasses the entire lifecycle of a server, from proper documentation and maintenance procedures to its eventual decommissioning. Mastering these areas ensures that an organization's IT infrastructure is not only functional but also resilient, well-documented, and prepared for any eventuality.
Data is one of an organization's most valuable assets, and protecting it through a solid backup and recovery strategy is a primary responsibility of a server administrator. The fundamental purpose of a backup is to create a copy of data that can be restored in the event of data loss. There are several types of backups. A full backup, as the name implies, copies all selected data. While it is the most complete and simplest to restore from, it is also the most time-consuming and requires the most storage space. For this reason, full backups are typically performed less frequently, perhaps on a weekly basis.
To supplement full backups, administrators use differential and incremental backups. A differential backup copies all data that has changed since the last full backup. Restoring from a differential backup requires only the last full backup and the latest differential backup, making the restoration process relatively quick. An incremental backup, on the other hand, copies only the data that has changed since the last backup of any type (full or incremental). This results in the fastest backup times and uses the least storage space. However, the restoration process is more complex, as it requires the last full backup and all subsequent incremental backups.
A widely adopted best practice for ensuring data resilience is the 3-2-1 backup rule. This rule states that you should have at least three copies of your data, store the copies on two different types of media, and keep one copy off-site. For example, the primary data resides on the server (copy 1), a local backup is made to a NAS device (copy 2, on different media), and another backup is replicated to a cloud storage provider or a secondary data center (copy 3, off-site). This strategy protects against a wide range of failure scenarios, from a simple drive failure to a complete site disaster like a fire or flood.
Go to testing centre with ease on our mind when you use CompTIA Server+ SK0-004 vce exam dumps, practice test questions and answers. CompTIA SK0-004 CompTIA Server+ certification practice test questions and answers, study guide, exam dumps and video training course in vce format to help you study with ease. Prepare with confidence and study using CompTIA Server+ SK0-004 exam dumps & practice test questions and answers vce from ExamCollection.
Purchase Individually


CompTIA SK0-004 Video Course

Top CompTIA Certifications













Top CompTIA Certification Exams
Site Search:

SPECIAL OFFER: GET 10% OFF

Pass your Exam with ExamCollection's PREMIUM files!
SPECIAL OFFER: GET 10% OFF
Use Discount Code:
MIN10OFF
A confirmation link was sent to your e-mail.
Please check your mailbox for a message from support@examcollection.com and follow the directions.

Download Free Demo of VCE Exam Simulator
Experience Avanset VCE Exam Simulator for yourself.
Simply submit your e-mail address below to get started with our interactive software demo of your free trial.
The exam dumps provided here are the best! They gave me the opportunity to prepare for the CompTIA test quickly and efficiently. You really don’t have to worry before the exam, because ExamCollection has provided these helpful learning resources. I went for the premium package and I don’t regret it.
If you are lost or don’t know where to start your preparation for the exam, these materials are meant for you. They contain everything you need to know about the test to pass it at your first attempt. This is how I managed to pass mine. Actually, I was surprised to meet the same questions in the actual exam.
The SK0-004 practice tests offered by ExamCollection are among the most effective study resources, which you need for this CompTIA exam. There are plenty of questions with answers that have a high possibility of being featured in the real exam. That is why I was able to pass the test with a high result. Thank you!
The VCE files for the SK0-004 exam offered me even more information than what I needed to excel. I’m happy to find this website and use its products. In the future, when I need to prepare for some other IT-related certification exam, I will refer to this platform for sure!