


Premium File
233 Q&A
$76.99$69.99
Splunk SPLK-1002 Exam Questions & Answers, Accurate & Verified By IT Experts
Instant Download, Free Fast Updates, 99.6% Pass Rate

SPLK-1002 Premium File: 233 Questions & Answers
Last Update: Jun 17, 2026
SPLK-1002 Training Course: 187 Video Lectures
SPLK-1002 PDF Study Guide: 879 Pages
$79.99
Splunk SPLK-1002 Exam Screenshots
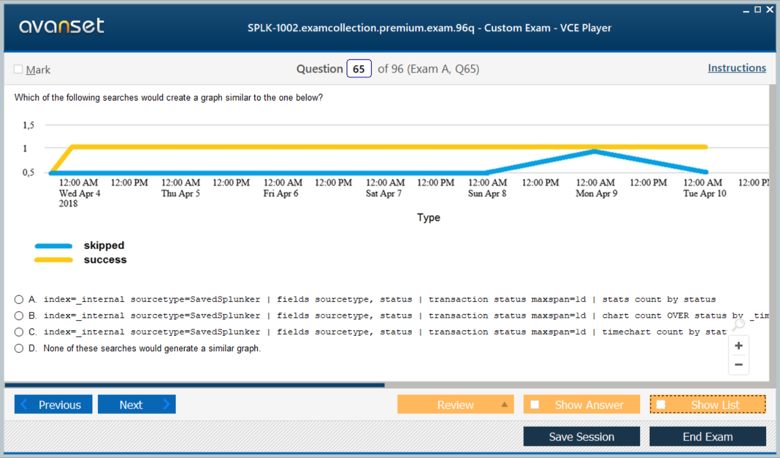
Splunk SPLK-1002 Practice Test Questions in VCE Format
| File | Votes | Size | Date |
|---|---|---|---|
File Splunk.actualtests.SPLK-1002.v2026-06-18.by.daniel.53q.vce |
Votes 1 |
Size 320.94 KB |
Date Jun 19, 2026 |
File Splunk.selftestengine.SPLK-1002.v2020-09-02.by.emma.27q.vce |
Votes 2 |
Size 36.27 KB |
Date Sep 02, 2020 |
File Splunk.test4prep.SPLK-1002.v2020-06-09.by.wangyong.25q.vce |
Votes 3 |
Size 208.66 KB |
Date Jun 09, 2020 |
Splunk SPLK-1002 Practice Test Questions, Exam Dumps
Splunk SPLK-1002 (Splunk Core Certified Power User) exam dumps vce, practice test questions, study guide & video training course to study and pass quickly and easily. Splunk SPLK-1002 Splunk Core Certified Power User exam dumps & practice test questions and answers. You need avanset vce exam simulator in order to study the Splunk SPLK-1002 certification exam dumps & Splunk SPLK-1002 practice test questions in vce format.
Splunk has established itself as one of the leading platforms for collecting, analyzing, and visualizing machine-generated data. Organizations across industries rely on it to gain real-time operational intelligence, monitor system performance, and detect anomalies before they escalate into serious problems. With the increasing volume of machine data generated daily, professionals who can effectively leverage Splunk are in high demand.
The SPLK-1002 exam, officially known as “Creating Data Models,” is a certification exam that tests an individual’s ability to design, build, and manage data models within Splunk. Successfully passing this exam demonstrates not only technical competence but also the ability to transform raw data into actionable insights. A data model in Splunk is essentially a hierarchical structure that organizes event data, enabling users to generate reports, dashboards, and pivot tables without repeatedly writing complex search queries. Mastering data models is a critical step toward efficiently analyzing large volumes of machine data.
Before creating and managing data models, it is crucial to understand the foundational concepts that govern them. These concepts form the backbone of effective data modeling in Splunk.
A data model in Splunk is a structured representation of event data organized into hierarchical objects and fields. These objects can be root objects or child objects, each containing specific fields and constraints that define their scope. Root objects represent the primary dataset, while child objects are subsets filtered according to specific criteria such as event type, host, or source. Fields are individual attributes or data points extracted from events, and they provide the context necessary for analysis and reporting.
Acceleration is a feature in Splunk that enhances the performance of data models. By precomputing and storing summaries of data, acceleration allows dashboards, pivot reports, and searches to execute more quickly. This is particularly important when working with large datasets or time-sensitive queries. Understanding when and how to apply acceleration can significantly improve the efficiency of your Splunk environment.
Constraints are rules applied to data model objects that define which events are included. Filters can be used to refine these constraints further, ensuring that only relevant data is captured in the model. Proper use of constraints and filters is essential for maintaining the accuracy and performance of data models.
A structured approach to exam preparation can make the difference between success and failure. It requires a combination of theoretical knowledge, practical experience, and strategic study habits.
The SPLK-1002 exam covers several critical areas, including the creation and management of data models, configuration of objects and constraints, utilization of fields and calculations, implementation of data model acceleration, and the design of pivot reports and dashboards. A deep understanding of these topics ensures you are prepared to answer both theoretical and scenario-based questions effectively.
Practical experience is crucial. Setting up a Splunk environment, either locally or through Splunk’s online sandbox, allows you to experiment with real datasets. Practice creating root and child objects, applying constraints, configuring calculated fields, and testing acceleration. Hands-on experience not only reinforces theoretical knowledge but also builds confidence in applying skills in a real-world context.
To prepare effectively, it is important to use high-quality resources. Official Splunk documentation, instructor-led courses, and practical exercises are invaluable. Focus on materials that provide real-world scenarios and examples, as they help bridge the gap between exam content and practical application.
Creating a robust data model involves a clear, step-by-step approach that ensures accuracy, efficiency, and scalability.
Before creating a data model, it is essential to understand its intended use. Will it be used for monitoring security events, analyzing IT operations, or generating business analytics? Defining the purpose informs the selection of datasets, the structure of objects, and the fields that need to be included.
Next, identify the datasets relevant to your objectives. Use Splunk’s search functionality to explore events and determine which fields are most important. Understanding the characteristics of your data will guide the creation of accurate and useful objects.
Root objects form the foundation of a data model. They represent the primary dataset and should be named clearly to reflect their purpose. Define constraints to include only the events that are relevant to the model. Properly designed root objects set the stage for efficient child object creation and subsequent reporting.
Child objects are subsets of root objects and allow for granular segmentation of data. For instance, a root object containing all firewall logs could have child objects representing allowed traffic, blocked traffic, and suspicious activity. This hierarchy helps organize data logically and simplifies the creation of pivot reports and dashboards.
Fields are the building blocks of data models. Add fields that capture essential information, such as source IP, destination IP, event type, or user ID. Calculated fields can also be used to generate metrics such as event counts, average response times, or error rates. Accurate field definition is critical for meaningful analysis and reporting.
After building your data model, it is important to test it thoroughly. Run searches, create pivot reports, and verify that results match expectations. Optimize constraints, adjust field definitions, and refine calculations to ensure the model performs efficiently and produces accurate insights.
Adhering to best practices ensures that your data models remain efficient, scalable, and maintainable.
Keep structures as simple as possible to avoid unnecessary complexity
Use descriptive names for root and child objects to enhance clarity
Apply acceleration only to models that are frequently accessed to improve performance without overloading system resources
Regularly monitor model performance to identify and resolve bottlenecks
Document your data models, including constraints, fields, and calculations, to facilitate collaboration and maintenance
Building and managing data models can present several challenges. Understanding common issues and strategies to address them is essential for success.
Large datasets can slow down searches and pivot reports. Use constraints, filters, and acceleration to manage performance and ensure timely query execution.
Some datasets may have intricate relationships between events. Breaking down complex relationships into smaller child objects helps maintain clarity and simplifies reporting.
Data models must evolve as datasets change. Regularly audit and update constraints, fields, and calculations to maintain accuracy and relevance.
One of the most powerful aspects of data models is their ability to drive pivot reports and dashboards. Pivot reports allow users to generate visualizations without writing complex searches, making Splunk accessible to non-technical stakeholders.
Select the appropriate dataset, including root and child objects, for the pivot
Choose relevant fields to answer specific business questions
Group and aggregate data to uncover trends and insights
Visualize the data using charts, tables, or dashboards to communicate findings effectively
Pivot reports enable decision-makers to interact with data directly, reducing dependence on manual searches and enhancing operational efficiency.
Use tags strategically to categorize events and simplify searches
Plan the hierarchy of root and child objects before building the model to avoid restructuring later
Keep a record of constraints and filters applied to objects to maintain transparency
Monitor acceleration summaries to ensure precomputed data remains accurate and useful
Continuously explore new datasets and scenarios to refine your modeling skills and stay current with best practices
After mastering the basics of data models, it is important to explore advanced concepts that enhance performance, scalability, and usability. Advanced data modeling techniques allow Splunk users to efficiently manage large datasets, generate more accurate reports, and build dashboards that provide actionable insights.
One of the key concepts in advanced data modeling is object inheritance. Child objects inherit fields and constraints from their parent objects, which reduces redundancy and simplifies maintenance. By carefully designing hierarchies, you can ensure consistency across datasets while allowing specific customization for subsets of data. For example, a root object representing all network traffic could have child objects for internal traffic, external traffic, and suspicious activity, each inheriting common fields like timestamp, host, and source but applying unique constraints or calculated fields.
Constraints are filters that define which events are included in a data model object. Advanced users often apply constraints strategically to optimize performance. Avoid overly broad constraints that could include unnecessary events, as this can slow down searches and pivot reports. Conversely, overly narrow constraints may omit valuable data. Balancing specificity and completeness is essential for high-quality data models. Constraints can also be dynamic, using macros or conditional searches to adjust automatically based on dataset characteristics.
Calculated fields are fields derived from existing event data using mathematical or conditional expressions. They enable users to create metrics, ratios, or status indicators without modifying the original events. Examples include calculating average response time, identifying failed login attempts, or deriving session durations. Transforming events through calculated fields simplifies analysis and reduces the need for repetitive search queries. Properly designed calculated fields improve dashboard performance and provide more meaningful insights for business or operational decision-making.
Data model acceleration is a critical technique for improving performance, especially with large or frequently queried datasets. Acceleration creates a summarized index that stores precomputed results, enabling faster pivot reports and dashboards. Advanced users optimize acceleration by carefully selecting which objects to accelerate, monitoring the size and update frequency of summaries, and configuring retention policies. It is also important to note that acceleration consumes system resources, so monitoring CPU and storage usage is essential to avoid performance bottlenecks.
Large datasets can present challenges for both data model creation and search performance. Splunk provides several strategies to handle high-volume data effectively. Indexing data properly, applying selective constraints, and using summary indexing or acceleration can significantly improve query times. Partitioning datasets by time, host, or event type also helps manage complexity. In practice, advanced users often combine multiple strategies to maintain responsiveness while preserving the completeness and accuracy of the data model.
Adhering to best practices ensures that advanced data models remain efficient, maintainable, and scalable.
Before creating data models, plan the hierarchy of root and child objects. A clear hierarchy reduces redundancy and simplifies maintenance. Document the hierarchy and rationale for object placement, making it easier for team members to understand the structure. Properly planned hierarchies improve both performance and usability.
Tags and event types provide additional layers of categorization and filtering. Tags are labels assigned to events that can be used in searches or pivots, while event types group similar events with shared characteristics. By combining tags, event types, and constraints, users can create highly targeted data models that are easier to navigate and query.
Regularly monitor the performance of data models, especially those that are accelerated. Analyze search times, pivot performance, and acceleration summaries to identify bottlenecks. Optimize by refining constraints, adjusting calculated fields, and selectively accelerating only the most frequently used objects. Performance monitoring ensures that data models continue to provide fast and accurate results as datasets grow.
Advanced data models can become complex, especially in large organizations. Maintaining clear documentation of object hierarchies, constraints, calculated fields, and acceleration settings is critical. Documentation facilitates collaboration among team members, ensures consistency, and reduces errors during updates or modifications.
Data models are not just theoretical constructs; they have practical applications across multiple domains. Understanding these applications helps users design models that deliver tangible value.
Data models can be used to monitor security events, such as failed logins, suspicious IP addresses, or abnormal network activity. Root objects may capture all security events, while child objects segment data by type, severity, or source. Calculated fields can identify trends, such as the frequency of failed logins per user or the duration of suspicious sessions. Accelerated models allow security teams to generate real-time dashboards and alerts, enhancing incident response.
In IT operations, data models provide insights into system performance, resource utilization, and service availability. Root objects may represent all server logs, while child objects focus on specific systems, applications, or error types. Calculated fields can track metrics like average CPU usage, memory utilization, or transaction times. Dashboards built from accelerated data models allow operations teams to detect anomalies, plan capacity, and optimize resource allocation.
Data models also support business analytics by transforming raw machine data into actionable insights. Sales, customer interactions, and transactional events can be modeled to reveal patterns, trends, and performance indicators. Child objects and calculated fields provide segmentation and derived metrics, enabling executives and analysts to make data-driven decisions. Pivot reports and dashboards present insights in a visual format, enhancing comprehension and decision-making speed.
Many organizations use data models to support compliance and audit reporting. Event logs related to access, transactions, or system changes can be structured into root and child objects with calculated fields highlighting anomalies or exceptions. Accelerated data models make it easier to generate regular audit reports efficiently, ensuring regulatory requirements are met without extensive manual effort.
Pivot reports allow users to explore and visualize data from models without writing SPL queries. Advanced techniques enhance their usefulness and efficiency.
Pivot reports can combine data from multiple objects, providing a holistic view of complex datasets. For example, network traffic models may combine firewall, IDS, and proxy logs to provide a unified security overview. Careful planning of object hierarchies and constraints ensures that combined pivots are accurate and performant.
Calculated fields and metrics can be directly used in pivot reports to generate advanced visualizations. Users can calculate averages, ratios, or custom performance metrics, enabling more nuanced analysis without additional SPL searches.
Advanced pivots often include conditional formatting to highlight anomalies or thresholds and drilldowns that allow users to explore the underlying raw events. These techniques improve readability, user engagement, and the speed at which insights are derived.
Even advanced users encounter challenges when working with data models. Awareness of common pitfalls helps prevent errors and maintain model integrity.
Too many child objects or unnecessary nesting can make data models difficult to manage. Keep hierarchies simple, logical, and purposeful, adding complexity only where it adds analytical value.
Accelerating too many objects or large datasets without monitoring resources can degrade system performance. Selectively accelerate only frequently used objects, and periodically review resource usage.
Complex models without documentation can lead to confusion and errors during updates. Maintain detailed records of hierarchies, constraints, and calculations to ensure clarity and continuity.
Beyond exam success, the true measure of proficiency in Splunk data models is the ability to apply skills in real-world scenarios. Practice by designing models for actual datasets, experimenting with complex hierarchies, implementing calculated fields, and building pivot dashboards. Continuous exploration of new use cases helps deepen understanding and keeps skills relevant in a rapidly evolving data landscape.
Passing the SPLK-1002 exam requires a combination of knowledge, hands-on practice, and exam strategy. Understanding how the exam evaluates your skills helps maximize performance and confidence.
The SPLK-1002 exam includes multiple-choice, multiple-response, and scenario-based questions. Some questions test theoretical knowledge, while others assess practical application. Familiarize yourself with the exam objectives and weighting, paying special attention to areas like creating and managing data models, configuring constraints, using calculated fields, and implementing acceleration.
A structured study schedule ensures all topics are covered and reduces last-minute cramming. Allocate time for theory, hands-on practice, and review. Focus on weaker areas while maintaining proficiency in stronger areas. Regular review of key concepts, such as object hierarchies, calculated fields, and pivot reports, reinforces understanding and retention.
Practical experience is critical for success. Create sample datasets and practice building root and child objects, applying constraints, and configuring calculated fields. Experiment with acceleration settings and generate pivot reports to test performance. Hands-on labs simulate real-world scenarios and prepare you for scenario-based exam questions.
Identify common pitfalls in the SPLK-1002 exam, such as misapplying constraints, overcomplicating hierarchies, or misunderstanding calculated field expressions. Learn tips for time management, interpreting scenario questions, and validating answers against the exam objectives. Reviewing these tips reduces errors and boosts confidence during the exam.
In both the exam and real-world environments, troubleshooting data models is an essential skill. Understanding common issues and their solutions ensures models remain accurate and efficient.
Errors may occur when data is missing, pivot reports show unexpected results, or acceleration fails. Begin troubleshooting by reviewing object constraints, field definitions, and hierarchical relationships. Ensure that root objects include all relevant events and that child objects are properly filtered.
Calculated fields may produce incorrect values if formulas are misapplied or fields contain unexpected data types. Test calculations with sample events and verify results. Simplify complex expressions into smaller components to isolate errors. Accurate calculated fields are critical for reporting and pivot functionality.
Data model performance issues often stem from overly broad constraints, unoptimized hierarchies, or excessive acceleration. Monitor search and pivot performance, and refine object structures or field selections. Consider partitioning datasets and limiting acceleration to high-priority objects. Efficient data models reduce query time and system load, ensuring responsive dashboards.
Data models must adapt as datasets grow or evolve. Regularly audit constraints, calculated fields, and hierarchies. Update object definitions to reflect changes in data sources, event types, or business requirements. Proactive maintenance ensures models continue to provide reliable insights and remain aligned with organizational needs.
Exam preparation is strengthened by understanding real-world applications of data models. Applying concepts to practical scenarios enhances comprehension and retention.
In a SOC, a data model may track network and endpoint security events. Root objects capture all security events, while child objects segment data by type, severity, or source. Calculated fields identify repeated failed logins, suspicious traffic patterns, or malware alerts. Accelerated models generate real-time dashboards, enabling analysts to detect and respond to incidents quickly.
Data models support monitoring of servers, applications, and network performance. Root objects include system logs, while child objects focus on error types, system components, or critical metrics. Calculated fields measure response times, resource utilization, and uptime percentages. Accelerated models provide operations teams with dashboards that highlight anomalies, enabling proactive management and issue resolution.
Data models can transform transactional and customer data into actionable business insights. Root objects may represent sales or user activity logs, with child objects segmenting data by region, product, or customer type. Calculated fields track revenue, conversion rates, or customer engagement metrics. Pivot dashboards allow stakeholders to visualize trends and make data-driven decisions without writing complex queries.
Organizations subject to regulatory requirements can use data models to streamline audit and compliance reporting. Root objects capture access logs or transaction data, while child objects focus on exceptions or critical events. Calculated fields flag anomalies or potential compliance breaches. Accelerated models allow auditors to generate accurate reports quickly, supporting regulatory adherence efficiently.
Beyond exam preparation, professional use of data models requires optimization for accuracy, performance, and scalability.
Design object hierarchies to reduce redundancy and simplify navigation. Avoid excessive nesting while ensuring logical grouping. Efficient hierarchies improve both model maintainability and pivot performance.
Select and define fields carefully, avoiding unnecessary or redundant fields that increase model complexity. Utilize calculated fields for derived metrics and transformations, keeping dashboards clean and focused.
Accelerate only frequently accessed objects to balance performance and resource usage. Monitor acceleration summaries and system resources regularly to prevent bottlenecks or excessive storage consumption.
Maintain detailed documentation of object hierarchies, constraints, calculated fields, and acceleration settings. Documentation supports team collaboration, reduces errors during updates, and ensures continuity when models are shared or transferred.
Regularly review model performance, update object definitions, and audit calculated fields. Proactive maintenance ensures models remain accurate, relevant, and performant as data sources or organizational requirements change.
Pivot reports transform data models into interactive visualizations that enable quick insights without SPL searches.
Combine multiple objects to create comprehensive views, apply calculated metrics directly in pivots, and use conditional formatting to highlight key trends or anomalies. Drilldowns allow users to explore underlying events for deeper analysis.
Accelerated data models power real-time dashboards for monitoring operations, security events, or business KPIs. Dashboards provide stakeholders with actionable insights quickly, enabling faster decisions and responses.
Pivot reports derived from well-structured data models support informed decision-making across departments. They reduce dependency on technical experts, allowing non-technical stakeholders to access and interact with data directly.
Scenario-based questions test practical application and problem-solving skills.
Understand the scenario fully before answering. Identify the key objective, constraints, and metrics being evaluated.
Visualize the required data model structure, including root and child objects, fields, and constraints. Consider acceleration needs and pivot reporting requirements.
Check that all fields, constraints, and calculated metrics align with the scenario. Ensure that solutions are practical and optimized for performance.
Allocate time wisely, answering easier questions first and revisiting complex scenarios. Use any remaining time to review calculations, hierarchies, and pivot logic.
Mastering Splunk data models at an advanced level requires not only technical knowledge but also strategic thinking, troubleshooting skills, and practical experience. By understanding exam strategies, identifying and resolving common issues, and applying concepts to real-world scenarios, professionals can maximize the value of data models in both testing and professional environments. Optimized hierarchies, effective calculated fields, strategic acceleration, and robust documentation ensure that data models are accurate, scalable, and high-performing. Leveraging pivot reports and dashboards provides actionable insights that drive operational excellence, enhance decision-making, and demonstrate the full power of Splunk in transforming raw machine data into structured intelligence.
Go to testing centre with ease on our mind when you use Splunk SPLK-1002 vce exam dumps, practice test questions and answers. Splunk SPLK-1002 Splunk Core Certified Power User certification practice test questions and answers, study guide, exam dumps and video training course in vce format to help you study with ease. Prepare with confidence and study using Splunk SPLK-1002 exam dumps & practice test questions and answers vce from ExamCollection.
Purchase Individually


Splunk SPLK-1002 Video Course

Top Splunk Certifications



Top Splunk Certification Exams
Site Search:

SPECIAL OFFER: GET 10% OFF

Pass your Exam with ExamCollection's PREMIUM files!
SPECIAL OFFER: GET 10% OFF
Use Discount Code:
MIN10OFF
A confirmation link was sent to your e-mail.
Please check your mailbox for a message from support@examcollection.com and follow the directions.

Download Free Demo of VCE Exam Simulator
Experience Avanset VCE Exam Simulator for yourself.
Simply submit your e-mail address below to get started with our interactive software demo of your free trial.
have read the comments about the vce file for SPLK-1002 exam… i think i’ll try out the material provided there as well….. hope it’s what I need….. i will just try to be safe by combining with other materials. i would advise everyone to do so!
@berry_berrie, i have used this site for various exams and their materials have never disappointed me! as well as the SPLK-1002 practice questions and answers… practice with them every day and they will help you pass your exam☺
I have never used this site before and so need your opinion about the validity of the materials they offer…..have you used the dump for SPLK-1002 exam? what can you say? Please, share……
I know that using practice test for SPLK-1002 exam should be the final stage in your prep process….do you agree???
@andy, from my previous experiences with different exams I learnt that dumps are very effective tools. I always got top quality and reliable materials from this site and gained really high scores in my tests. the braindump for SPLK-1002 is no exception…simply find the most updated one...this website provides free materials….
i wonder whether the vce file for SPLK-1002 exam will be worth using… i would really like to succeed in this splunk exam in my first attempt.. can it help me with this??
I'd like to prepare myself to tackle SPLK-1002 (Splunk Core Certified Power User) certification exam well in advance, please.