Pass Your Splunk Enterprise Certified Admin Certification Easy!
Splunk Enterprise Certified Admin Certification Exams Questions & Answers, Accurate & Verified By IT Experts
Instant Download, Free Fast Updates, 99.6% Pass Rate.
Splunk Enterprise Certified Admin Certification Exams Screenshots
Splunk Enterprise Certified Admin Product Reviews
Download Free Splunk Enterprise Certified Admin Practice Test Questions VCE Files
| Exam | Title | Files |
|---|---|---|
Exam SPLK-1003 |
Title Splunk Enterprise Certified Admin |
Files 6 |
Splunk Enterprise Certified Admin Certification Exam Dumps & Practice Test Questions
Prepare with top-notch Splunk Enterprise Certified Admin certification practice test questions and answers, vce exam dumps, study guide, video training course from ExamCollection. All Splunk Enterprise Certified Admin certification exam dumps & practice test questions and answers are uploaded by users who have passed the exam themselves and formatted them into vce file format.
Splunk Enterprise Certified Admin for IT Infrastructure & Security Analytics
Splunk Enterprise is a robust platform designed for collecting, analyzing, and visualizing machine-generated data. The Splunk Enterprise Certified Admin certification is a recognition of an individual's ability to effectively manage and optimize a Splunk environment. Professionals with this certification can handle system installation, configuration, monitoring, and maintenance to ensure operational efficiency. The role of a Splunk administrator extends beyond basic system management to include performance tuning, user management, data input configuration, and security enforcement. Understanding these core concepts is essential for IT professionals who aim to leverage the platform to its full potential.
Splunk Admin Basics
The foundation of Splunk administration involves understanding how the platform operates and how its components interact. A Splunk administrator must be familiar with the architecture, including indexers, search heads, forwarders, and deployment servers. Each component has a specific function in data collection, indexing, and search operations. The administrator's responsibility is to ensure that these components are properly installed, configured, and maintained. Proficiency in Splunk’s basic commands, search processing language, and monitoring tools is critical for day-to-day operations. Administrators must also understand the various types of Splunk instances and their roles in distributed environments.
License Management
License management is a crucial aspect of maintaining a compliant and efficient Splunk deployment. Each Splunk environment requires a license that defines the volume of data that can be indexed daily and the duration of license validity. Administrators are responsible for monitoring license usage, identifying trends in data ingestion, and ensuring that license violations do not occur. Proper license management prevents system interruptions and allows for scalable growth of the Splunk deployment. Administrators must also be capable of configuring license pools, managing license warnings, and optimizing data indexing practices to align with license constraints.
Splunk Configuration Files
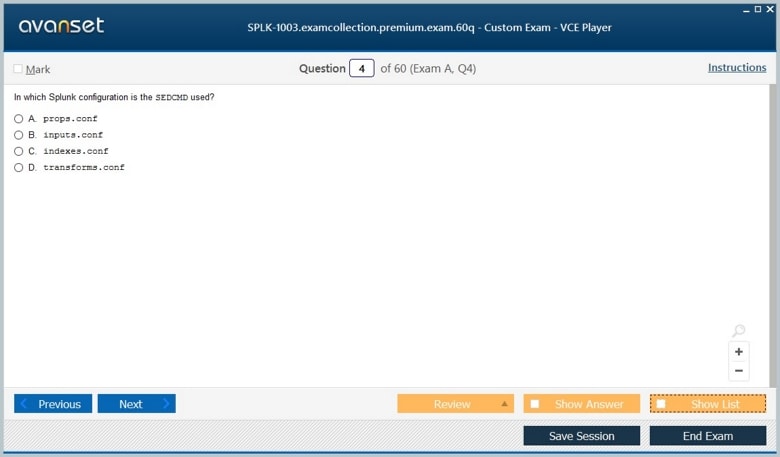
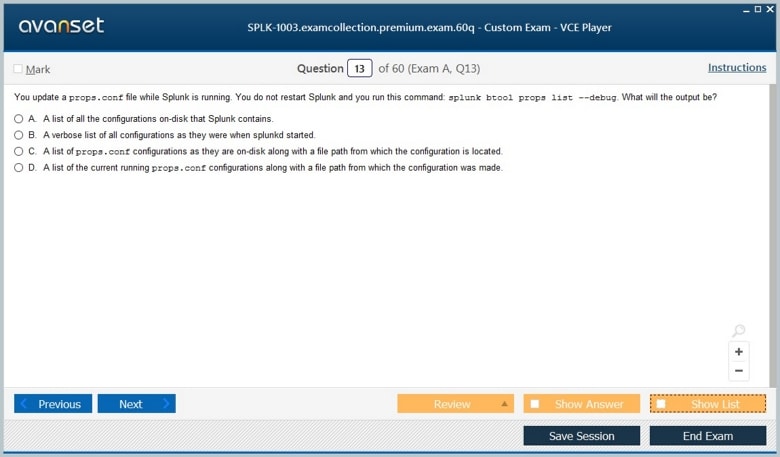
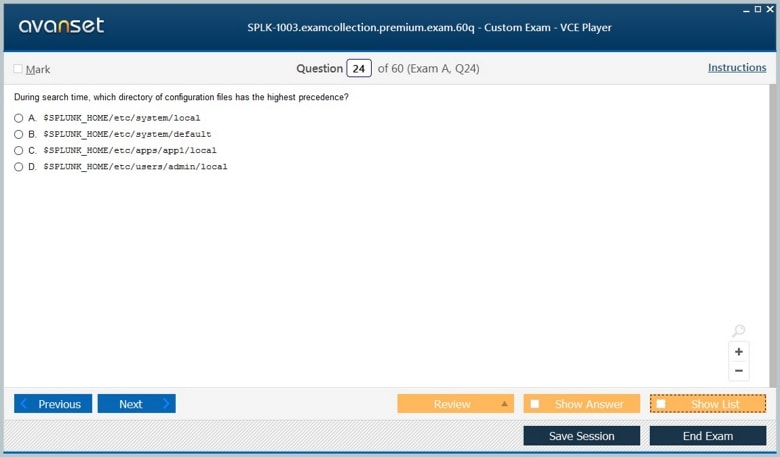
Splunk relies heavily on configuration files to define its behavior and settings. These files control system operations, including indexing, user permissions, data inputs, and log parsing. An administrator must be adept at locating, understanding, and editing these configuration files while maintaining system stability. Key files include inputs.conf for data input configurations, props.conf for data parsing rules, and outputs.conf for defining forwarding behavior. Administrators must understand the hierarchy of configuration files, how to prioritize settings, and the effects of modifications in distributed environments. Proper configuration management ensures consistent system behavior and avoids conflicts across multiple Splunk instances.
Splunk Indexes
Indexes are the core structure within Splunk that store and organize incoming data. A Splunk administrator must understand how to create, configure, and manage indexes to optimize search performance and storage efficiency. Indexes are used to categorize and isolate data, which enhances the speed and accuracy of searches. Administrators are responsible for setting retention policies, managing index sizes, and monitoring index health. Understanding index types, such as event and metric indexes, and the implications of data aging, is critical for maintaining a high-performing Splunk environment. Proper indexing practices also improve the platform’s ability to generate accurate reports, dashboards, and alerts.
Splunk User Management
User management is a fundamental responsibility of a Splunk administrator. It involves creating and maintaining user accounts, assigning roles, and ensuring that each user has the appropriate level of access to data and system functionalities. Splunk provides a role-based access control model, which allows administrators to define specific permissions for groups of users. Administrators must understand the default roles, such as user, power, and admin, and be able to create custom roles to meet organizational requirements. Proper user management ensures data security, prevents unauthorized access, and allows different teams to work efficiently without interfering with each other’s work. Administrators must also be able to audit user activity, manage password policies, and ensure that inactive accounts are disabled to maintain compliance and security standards.
Splunk Authentication Management
Authentication management is closely related to user management and focuses on verifying the identity of users accessing the Splunk environment. Splunk supports multiple authentication mechanisms, including internal Splunk authentication, LDAP, and Single Sign-On solutions. Administrators need to configure authentication settings to integrate with organizational directories, ensuring that user credentials are validated securely. Configuring LDAP involves mapping user roles from the directory to Splunk roles and ensuring synchronization between the systems. Administrators must also implement secure password policies, manage authentication tokens, and monitor authentication logs for suspicious activity. Proper authentication management helps prevent security breaches and ensures that only authorized personnel can access sensitive data and system controls.
Getting Data In
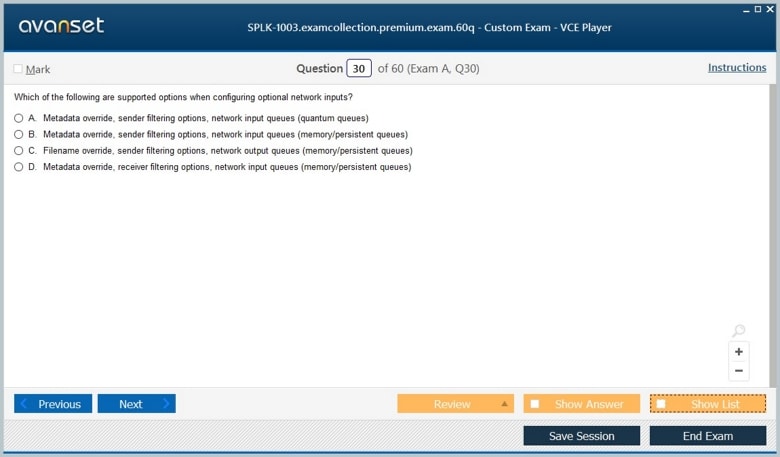
Ingesting data is one of the most critical tasks for a Splunk administrator. Splunk collects and indexes data from various sources, including logs, metrics, and application data. Administrators must be proficient in identifying data sources, configuring inputs, and ensuring that data is collected in a reliable and efficient manner. Splunk supports different types of inputs, such as file monitoring, network data streams, scripts, and APIs. Understanding how to configure inputs and set up forwarders to send data to indexers is essential for maintaining a consistent and high-performing data pipeline. Administrators must also be able to monitor data ingestion, troubleshoot missing or delayed data, and optimize input configurations to reduce system resource usage while maintaining data accuracy.
Distributed Search Architecture
Distributed search is a key feature of Splunk that allows searches to be executed across multiple indexers in a scalable environment. A Splunk administrator must understand how distributed search operates and how to configure search heads, indexers, and search peers to optimize performance. This includes knowledge of search affinity, search quotas, and load balancing to ensure that searches return results quickly and accurately. Administrators are also responsible for managing search head clustering, which provides high availability and failover capabilities. Understanding the distributed search architecture enables administrators to design and maintain a scalable Splunk deployment that can handle large volumes of data while providing fast and reliable search performance for users across the organization.
Staging and Parsing Data
Staging and parsing data are critical steps in preparing raw data for indexing in Splunk. Staging involves temporarily holding incoming data in a structured format before it is indexed, allowing administrators to apply transformations and validations. Parsing refers to the process of breaking down raw data into meaningful components, such as timestamps, fields, and event types. Administrators use configuration files to define parsing rules and ensure that data is correctly interpreted by Splunk. This includes setting source types, applying field extractions, and configuring line-breaking rules to separate events accurately. Proper staging and parsing are essential for maintaining data quality, enabling accurate searches, and supporting advanced analytics. Administrators must continuously monitor parsing configurations to adapt to changes in data formats or sources, ensuring that the system remains reliable and consistent.
Configuring Forwarders
Forwarders are essential components in a Splunk environment that enable the collection and transmission of data from various sources to the indexers. Configuring forwarders involves setting up both universal forwarders and heavy forwarders depending on the type and volume of data. Universal forwarders are lightweight agents installed on source systems to send raw data efficiently, while heavy forwarders can parse and filter data before sending it to the indexers. Administrators must understand the installation process, configuration files, and deployment strategies for forwarders. Proper configuration includes defining the data inputs, setting up forwarding destinations, and ensuring secure communication between forwarders and indexers. Administrators must also validate that the forwarded data is correctly indexed and searchable, ensuring reliability and consistency across the environment.
Forwarder Management
Managing forwarders is a critical responsibility of a Splunk administrator. This involves monitoring the performance of forwarders, troubleshooting connectivity issues, and ensuring that data is being transmitted without delays or losses. Administrators must maintain an inventory of all forwarders, including their versions, configurations, and associated data sources. Forwarder management also includes applying updates, patches, and security configurations to ensure that all agents operate effectively. In distributed environments, administrators use deployment servers to manage configurations centrally, allowing changes to propagate automatically to multiple forwarders. Effective forwarder management ensures high availability of data, reduces operational overhead, and maintains the integrity of the data pipeline.
Monitor Inputs
Monitor inputs are configurations that allow Splunk to continuously collect data from files, directories, and other sources. Administrators define monitor inputs in configuration files to specify the path, frequency, and type of data to collect. Splunk automatically tracks changes in monitored files, indexing new data as it becomes available. Administrators must understand how to optimize monitor inputs to balance system performance with data completeness. This includes setting appropriate file reading intervals, handling log rotation, and filtering unnecessary data. Proper configuration of monitor inputs ensures that Splunk captures all relevant information while minimizing resource consumption. Administrators must also monitor input performance and adjust configurations as needed to accommodate growing data volumes.
Network and Scripted Inputs
Network and scripted inputs allow Splunk to ingest data from network streams and external scripts. Network inputs include syslog, TCP, and UDP streams, which are commonly used to collect log data from servers, applications, and security devices. Scripted inputs involve executing custom scripts that produce data for Splunk to index. Administrators must configure network ports, define source types, and ensure secure transmission for network inputs. Scripted inputs require knowledge of scripting languages and the ability to integrate with external applications and systems. Effective configuration of these inputs enables administrators to capture real-time data from diverse sources, supporting comprehensive monitoring and analytics across the organization. Monitoring the performance and reliability of network and scripted inputs is essential to maintain data accuracy and timeliness.
Agentless Inputs
Agentless inputs are methods of collecting data without installing a forwarder on the source system. This approach is often used for systems where installing an agent is not feasible or desired. Splunk supports agentless inputs through protocols such as SNMP, REST APIs, and database queries. Administrators must configure credentials, connection parameters, and polling intervals to ensure reliable data collection. Agentless inputs provide flexibility for monitoring remote systems, cloud services, and network devices. Administrators must monitor agentless inputs to verify that data is consistently collected and integrated into the indexers. Proper configuration and maintenance of agentless inputs allow organizations to expand their data monitoring capabilities without introducing additional agents or system overhead.
Fine Tuning Inputs
Fine tuning data inputs is an ongoing task for Splunk administrators to ensure efficient data collection and indexing. This process involves adjusting input settings to optimize performance, reduce latency, and minimize resource consumption. Administrators analyze data volumes, ingestion rates, and system metrics to identify bottlenecks or inefficiencies. Fine tuning may include adjusting file monitoring intervals, filtering unnecessary data, compressing logs, or configuring batch indexing. Administrators also ensure that time stamps, field extractions, and source types are correctly applied to incoming data. Regular fine tuning of inputs enhances search performance, improves system stability, and allows organizations to manage large and growing datasets effectively. Continuous monitoring and adjustment of input configurations are essential to maintain an optimized Splunk environment.
Parsing Phase and Data
Parsing is a critical stage in the Splunk data pipeline that transforms raw data into structured events. During the parsing phase, administrators define rules for extracting fields, identifying timestamps, and segmenting events. This process involves configuring props.conf and transforms.conf files to ensure accurate data interpretation. Parsing enables Splunk to index data efficiently, support accurate searches, and generate meaningful reports. Administrators must also handle complex scenarios, such as multi-line events, nested data, and inconsistent formats. Effective parsing ensures that the indexed data is reliable and usable for analytics, monitoring, and alerting. Administrators continuously review and refine parsing configurations to adapt to changes in data sources and maintain the integrity of the Splunk environment.
Manipulating Raw Data
Manipulating raw data is a core responsibility of a Splunk administrator and involves transforming incoming data into a format that is optimized for indexing and searching. This process begins with understanding the structure of raw data, identifying key fields, and applying parsing rules to extract meaningful information. Administrators use configuration files such as props.conf and transforms.conf to define extraction patterns, apply regular expressions, and create calculated fields. Data manipulation also includes timestamp recognition, event breaking, and field renaming to ensure that the data is consistent and searchable. Effective manipulation of raw data improves the accuracy of searches, dashboards, and reports. Administrators must continuously monitor incoming data streams to adapt parsing rules to changes in data formats and maintain the quality and usability of the indexed information.
Advanced Indexing Techniques
Advanced indexing techniques are essential for managing large volumes of data efficiently in Splunk Enterprise. Administrators must understand the different types of indexes, including event indexes, metric indexes, and summary indexes, and determine how to structure them for optimal search performance. This includes setting retention policies, defining index sizes, and partitioning data based on source or type. Advanced indexing also involves using data model acceleration and summary indexing to precompute key metrics, reducing search times and improving performance. Administrators are responsible for monitoring index health, managing frozen and archived data, and ensuring that storage resources are used effectively. Proper implementation of advanced indexing techniques enables organizations to handle high volumes of machine data while maintaining fast and reliable search capabilities.
Data Retention and Storage Management
Data retention and storage management are critical for maintaining an efficient and compliant Splunk deployment. Administrators define retention policies that determine how long data is stored in hot, warm, cold, and frozen buckets. Managing storage involves monitoring disk usage, balancing data across indexers, and implementing archiving strategies for long-term storage. Administrators must also ensure that data deletion processes follow organizational policies and regulatory requirements. Storage optimization techniques include compressing older data, using efficient file formats, and distributing data to multiple storage volumes. Effective data retention and storage management reduce system costs, prevent performance degradation, and ensure that historical data remains accessible for analysis and reporting.
Distributed Search Optimization
Distributed search is a feature that allows Splunk to execute searches across multiple indexers and search heads in a scalable environment. Optimizing distributed search is a key responsibility of administrators to ensure fast and accurate search results. This involves configuring search head clustering, load balancing search requests, and setting search quotas to prevent system overload. Administrators must monitor search performance, identify bottlenecks, and adjust configurations to improve efficiency. Techniques such as search affinity, parallel searches, and scheduled searches help optimize resource usage and reduce latency. Properly managing distributed search ensures that large-scale deployments can handle high volumes of data and complex queries while maintaining consistent performance and reliability.
Performance Tuning of Splunk Components
Performance tuning is a continuous process aimed at maximizing the efficiency and responsiveness of the Splunk environment. Administrators monitor system metrics such as CPU usage, memory consumption, disk I/O, and indexing rates to identify potential performance issues. Tuning involves adjusting configurations for indexers, search heads, forwarders, and deployment servers to optimize resource allocation. Administrators may also implement caching strategies, adjust search concurrency limits, and optimize knowledge objects such as saved searches, macros, and event types. Performance tuning ensures that searches return results quickly, dashboards update in real time, and alerts are triggered without delay. Continuous monitoring and adjustment are essential to maintaining a stable and high-performing Splunk deployment.
Monitoring and Troubleshooting Performance Issues
Monitoring and troubleshooting performance issues are essential skills for a Splunk administrator. Administrators must proactively track the health of all Splunk components, including indexers, search heads, forwarders, and network connections. Tools such as internal logs, monitoring consoles, and system dashboards help identify slow searches, high resource usage, and indexing delays. Troubleshooting may involve analyzing search patterns, identifying problematic configurations, and resolving conflicts between data inputs or system processes. Administrators must also implement strategies for load balancing, scaling, and system tuning to prevent recurring performance problems. Effective monitoring and troubleshooting maintain system reliability, improve user experience, and ensure that organizational data is available and actionable at all times.
Implementing Best Practices for Data Optimization
Implementing best practices for data optimization is crucial for maintaining the effectiveness of a Splunk environment. Administrators must ensure that data is collected efficiently, indexed properly, and stored in a way that supports fast searches and reporting. Best practices include defining source types accurately, applying field extractions, normalizing data, and reducing unnecessary data ingestion. Administrators also implement strategies for managing high-volume sources, such as using event sampling, summary indexing, and data model acceleration. Following best practices helps prevent performance bottlenecks, reduces storage overhead, and ensures that users can access relevant insights quickly. Continuous review and improvement of data handling practices are necessary to adapt to changing business needs and evolving data sources.
Knowledge Objects in Splunk
Knowledge objects are critical components in Splunk that allow administrators to structure, enrich, and analyze data effectively. These objects include saved searches, event types, tags, lookups, macros, field extractions, and data models. Administrators use knowledge objects to create reusable and consistent definitions that enhance search accuracy and efficiency. Saved searches allow repetitive queries to be executed automatically, supporting reporting, alerting, and dashboard generation. Event types categorize related events, making it easier to search for and analyze specific data patterns. Tags provide additional metadata for events, enhancing search capabilities across multiple data sources. Lookups enrich raw data by adding reference information from external sources. Field extractions define specific data points within events for more granular analysis. Macros simplify complex search queries by encapsulating reusable search logic. Data models organize structured and categorical data for accelerated searches and advanced analytics. Understanding and managing knowledge objects are essential for enabling consistent and efficient use of Splunk across an organization.
Creating and Managing Dashboards
Dashboards are visual representations of data in Splunk that provide insights into operational performance, security, and business processes. Administrators are responsible for creating and managing dashboards to ensure that relevant information is accessible to users in a clear and actionable format. Dashboards can include charts, tables, maps, and event lists, all of which can be configured to update in real time. Administrators define the data sources, apply appropriate visualizations, and arrange components to provide a coherent and informative view of the environment. Advanced dashboard management includes using tokens, drilldowns, and dynamic panels to allow users to interact with data and customize their experience. Maintaining dashboards requires monitoring their performance, ensuring that queries do not overload the system, and updating visualizations to reflect changing business requirements.
Configuring Alerts
Alerts are automated notifications that inform users of specific conditions or events within the Splunk environment. Administrators configure alerts to monitor critical thresholds, system anomalies, or business metrics. Alerts can be triggered based on scheduled searches, real-time searches, or conditional logic defined in saved searches. When an alert is triggered, it can perform various actions such as sending email notifications, executing scripts, or triggering webhooks. Administrators must carefully define alert conditions to avoid false positives or unnecessary notifications while ensuring that important events are promptly reported. Alert management also involves reviewing historical alerts, fine-tuning search queries, and optimizing performance to ensure that alert processing does not negatively impact system resources. Effective alert configuration enhances operational awareness, supports proactive problem resolution, and improves overall system reliability.
Security Configurations
Security configurations are a vital responsibility of a Splunk administrator to protect sensitive data and maintain compliance with organizational policies. Administrators implement role-based access controls, ensuring that users only have access to data and functionalities required for their roles. They configure authentication methods, enforce strong password policies, and integrate Splunk with external identity management systems. Administrators also monitor audit logs, track user activity, and configure alerts for unauthorized access attempts or suspicious behavior. Securing data in transit and at rest is critical, and administrators may implement encryption, secure network protocols, and secure storage practices. Security configurations extend to knowledge objects, dashboards, and alerts to ensure that sensitive information is only accessible to authorized users. Maintaining a secure Splunk environment requires ongoing monitoring, review of access policies, and proactive mitigation of potential vulnerabilities.
System Maintenance and Monitoring
System maintenance is essential to ensure the stability, performance, and reliability of a Splunk deployment. Administrators regularly monitor system health, including CPU usage, memory utilization, disk space, and indexing rates. They perform routine maintenance tasks such as upgrading Splunk software, applying patches, and managing deployment servers. Maintenance also involves reviewing configuration changes, validating system logs, and addressing errors or warnings reported by Splunk. Monitoring dashboards, alerts, and performance metrics help administrators identify potential issues before they impact users. Administrators also manage backup and recovery procedures to ensure data integrity in case of system failures. Regular system maintenance and monitoring maintain operational efficiency, prevent downtime, and support the scalability of the Splunk environment.
Troubleshooting and Optimization
Troubleshooting is a critical skill for Splunk administrators, as it ensures that system issues are identified and resolved promptly. Administrators analyze system logs, monitor search performance, and investigate anomalies in indexing, data ingestion, and search results. Troubleshooting may involve resolving configuration conflicts, addressing network or connectivity issues, and optimizing system resources. Optimization complements troubleshooting by improving the performance and efficiency of the Splunk environment. Administrators optimize search queries, fine-tune indexing strategies, and balance workloads across indexers and search heads. Effective troubleshooting and optimization enhance the overall reliability and responsiveness of the platform, ensuring that users can access accurate and timely data insights without delays.
Scaling and High Availability
Scaling and high availability are essential considerations for large Splunk deployments that handle significant data volumes and support critical business operations. Administrators design architectures that allow horizontal scaling by adding indexers or search heads to distribute workloads efficiently. High availability configurations include search head clustering, indexer clustering, and forwarder load balancing to prevent single points of failure. Administrators monitor cluster health, manage replication, and ensure synchronization between nodes to maintain data consistency and availability. Scaling strategies also include capacity planning, resource allocation, and performance monitoring to accommodate growing data volumes. Proper implementation of scaling and high availability ensures that the Splunk environment can handle increasing demands while providing uninterrupted access to data and analytics.
Backup and Disaster Recovery
Backup and disaster recovery are crucial for protecting the Splunk environment against data loss and system failures. Administrators develop and implement strategies for backing up configuration files, indexed data, and knowledge objects. Disaster recovery plans include restoring data to new environments, reconfiguring indexers and search heads, and validating system functionality after recovery. Administrators test backup and recovery procedures regularly to ensure they are effective and can meet organizational recovery time objectives. Effective backup and disaster recovery planning minimizes downtime, prevents data loss, and ensures business continuity. Administrators must also coordinate with IT teams to integrate Splunk recovery processes with broader organizational disaster recovery strategies.
Continuous Improvement and Best Practices
Continuous improvement involves regularly evaluating the Splunk environment and implementing best practices to enhance performance, security, and usability. Administrators review data ingestion methods, indexing strategies, search performance, and knowledge object configurations to identify areas for optimization. They adopt new features, update configurations, and refine workflows to meet evolving organizational requirements. Best practices include maintaining clear documentation, monitoring system health, enforcing security policies, and training users on effective Splunk usage. Continuous improvement ensures that the Splunk deployment remains scalable, efficient, and aligned with business objectives. Administrators who follow best practices support operational excellence and maximize the value of Splunk as a data analytics platform.
Final thoughts
The Splunk Enterprise Certified Admin (SPLK-1003) certification is a cornerstone for IT professionals aiming to demonstrate their expertise in managing and optimizing Splunk environments. It validates a comprehensive understanding of system architecture, data ingestion, indexing, search optimization, and administration best practices. Achieving this certification proves that an individual can efficiently handle operational challenges, ensure data integrity, implement security measures, and optimize performance across complex Splunk deployments.
The role of a Splunk administrator extends beyond technical configuration to include strategic data management, operational monitoring, and proactive troubleshooting. Certified administrators are capable of configuring forwarders, managing users, creating dashboards, implementing alerts, and maintaining high availability and disaster recovery procedures. Their expertise enables organizations to leverage Splunk as a powerful platform for real-time insights, security monitoring, operational intelligence, and data-driven decision-making.
In addition to technical skills, the certification highlights an administrator’s ability to adopt best practices, ensure compliance, and continuously improve the Splunk environment. This level of proficiency is highly valued in roles such as system administration, IT operations, security operations, and data engineering. Certified administrators not only maintain system reliability but also enable organizations to extract maximum value from their machine data.
Overall, the Splunk Enterprise Certified Admin certification equips professionals with the knowledge, practical skills, and confidence to manage complex Splunk deployments efficiently. It positions them as key contributors to organizational success, driving operational efficiency, security, and data-driven insights.
ExamCollection provides the complete prep materials in vce files format which include Splunk Enterprise Certified Admin certification exam dumps, practice test questions and answers, video training course and study guide which help the exam candidates to pass the exams quickly. Fast updates to Splunk Enterprise Certified Admin certification exam dumps, practice test questions and accurate answers vce verified by industry experts are taken from the latest pool of questions.


Splunk Splunk Enterprise Certified Admin Video Courses

Top Splunk Certifications



Top Splunk Certification Exams
Site Search:



