


Premium File
349 Q&A
$76.99$69.99
Google Professional Data Engineer Exam Questions & Answers, Accurate & Verified By IT Experts
Instant Download, Free Fast Updates, 99.6% Pass Rate

Professional Data Engineer Premium File: 349 Questions & Answers
Last Update: Jul 11, 2026
Professional Data Engineer Training Course: 201 Video Lectures
Professional Data Engineer PDF Study Guide: 543 Pages
$79.99
Google Professional Data Engineer Exam Screenshots
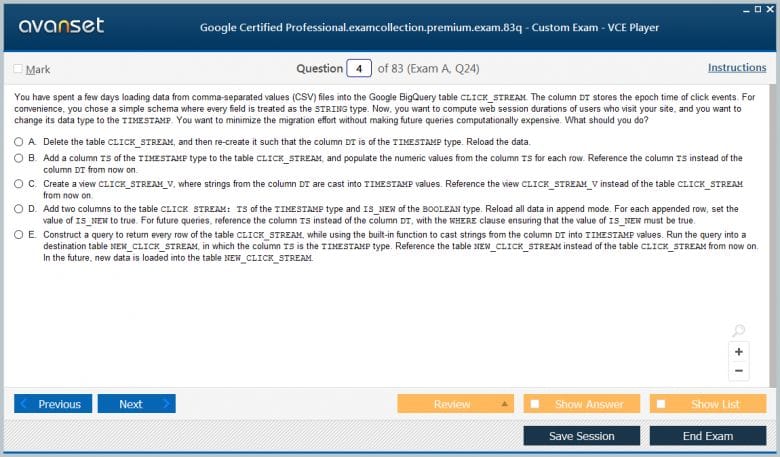
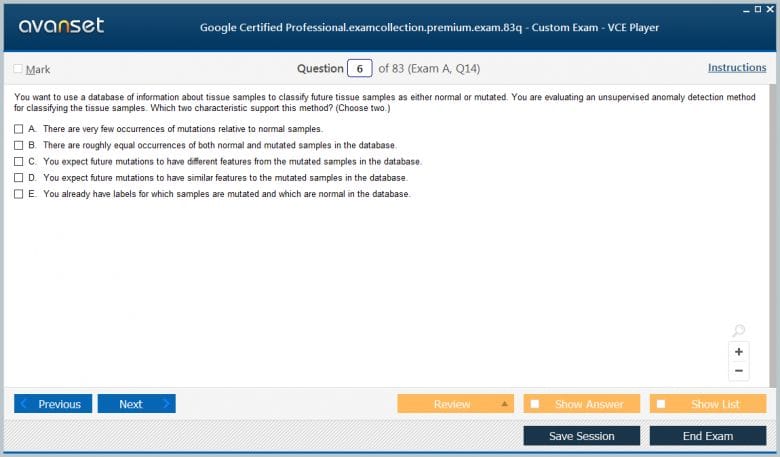
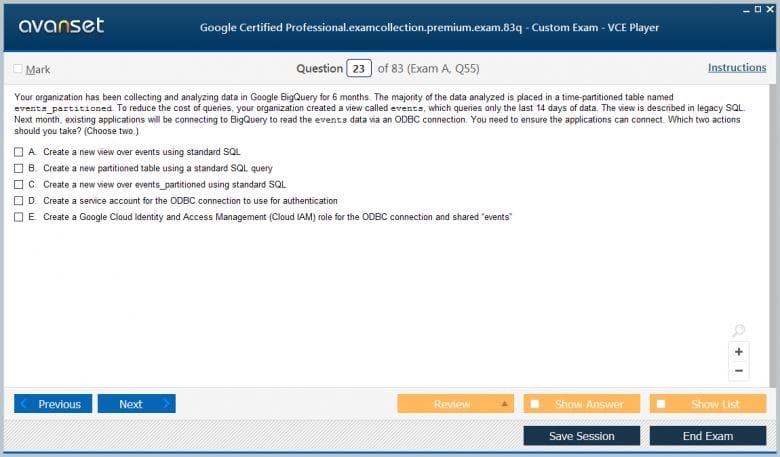
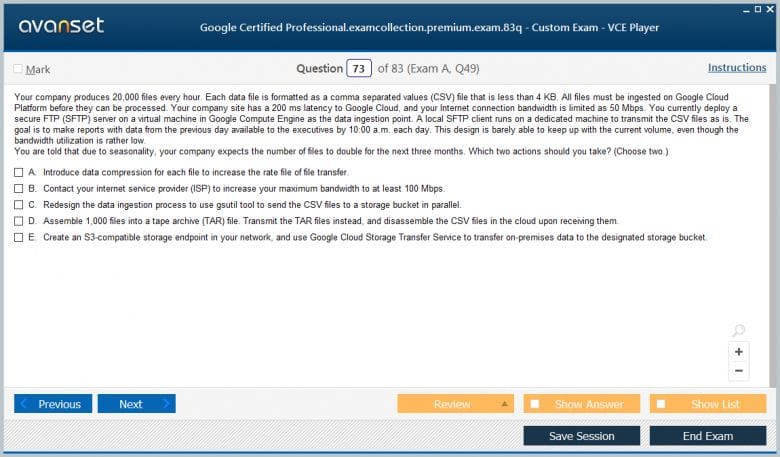
Google Professional Data Engineer Practice Test Questions in VCE Format
| File | Votes | Size | Date |
|---|---|---|---|
File Google.braindumps.Professional Data Engineer.v2026-06-02.by.annabelle.109q.vce |
Votes 1 |
Size 1.37 MB |
Date Jun 02, 2026 |
File Google.examdumps.Professional Data Engineer.v2021-12-27.by.christopher.103q.vce |
Votes 1 |
Size 272.55 KB |
Date Dec 27, 2021 |
File Google.examdumps.Professional Data Engineer.v2021-10-15.by.zhangyan.99q.vce |
Votes 1 |
Size 281.81 KB |
Date Oct 15, 2021 |
File Google.certkey.Professional Data Engineer.v2021-04-19.by.charlotte.93q.vce |
Votes 1 |
Size 406.26 KB |
Date Apr 19, 2021 |
File Google.Prepaway.Professional Data Engineer.v2019-09-09.by.Willie.86q.vce |
Votes 4 |
Size 274.04 KB |
Date Sep 16, 2019 |
File Google.Actualtests.Professional Data Engineer.v2018-11-08.by.Travis.27q.vce |
Votes 14 |
Size 174.69 KB |
Date Nov 16, 2018 |
Google Professional Data Engineer Practice Test Questions, Exam Dumps
Google Professional Data Engineer (Professional Data Engineer on Google Cloud Platform) exam dumps vce, practice test questions, study guide & video training course to study and pass quickly and easily. Google Professional Data Engineer Professional Data Engineer on Google Cloud Platform exam dumps & practice test questions and answers. You need avanset vce exam simulator in order to study the Google Professional Data Engineer certification exam dumps & Google Professional Data Engineer practice test questions in vce format.
For those who may be wondering if they are ready, or if it is achievable with a busy work schedule or limited experience with certain GCP services, let me reassure you: with the right preparation, persistence, and dedication, success is within your reach. This certification is a challenging one, and to succeed, it’s important to acknowledge that it demands more than just surface-level knowledge. It requires a comprehensive grasp of both theoretical concepts and practical skills that can be applied in real-world data engineering environments. With the right preparation, anyone can achieve their goal of becoming a Google Cloud Professional Data Engineer.
As with any journey, the first step toward success is understanding the scale of the challenge. The Google Cloud Professional Data Engineer exam is a 50-question multiple-choice test that assesses one’s knowledge and skills in managing and designing data systems using Google Cloud Platform (GCP). It focuses on your ability to design robust, scalable, and efficient data systems, optimize performance, and ensure cost-effective management of cloud-based data systems. Unlike other certifications, it does not have case study questions, which means that the exam is more focused on theoretical knowledge than on practical problem-solving through scenarios.
For me, the exam’s scope presented an initial challenge. Though I had worked with Google Cloud for about 3.5 years, my experience was limited to certain tools such as BigQuery, Data Fusion, and Composer. These tools were vital to the exam, but there were several other important products within the GCP ecosystem that I had not yet had the chance to master. This was a significant gap in my knowledge, and addressing it was going to be crucial for my success. The certification exam demands a working understanding of many tools, each with its own nuances, best practices, and performance optimization strategies.
The first challenge, as I realized early on, was not just the depth of knowledge required, but also the breadth. Google Cloud's suite of data engineering services is vast, and the exam requires you to have an understanding of everything from data storage to data pipelines, machine learning models, and even data governance. This meant that in order to succeed, I needed to become highly familiar with tools and services I had not yet worked with extensively, such as Cloud Pub/Sub, Cloud Spanner, and Dataflow, among others. The exam is less about memorizing facts and more about being able to demonstrate how you would approach a range of different cloud-based data engineering problems.
This realization set the tone for how I approached my preparation. I needed a strategy that would not only fill my knowledge gaps but also ensure I could apply that knowledge in practice. My preparation needed to be comprehensive, systematic, and well-paced. I had to break down the entire study process into manageable chunks, ensuring that I didn’t get overwhelmed by the sheer volume of material I needed to learn. Having a clear roadmap in place was essential for keeping me on track and motivated throughout the entire journey.
Like any ambitious project, success in this certification exam required a well-thought-out roadmap. I started by assessing my strengths and weaknesses. I was fortunate enough to have a solid understanding of the basics of GCP, particularly tools like BigQuery, Data Fusion, and Composer, which I had used in my previous roles. However, my weaknesses lay in the more advanced aspects of the GCP ecosystem, which were crucial for the exam. For example, I had limited experience with Cloud Pub/Sub, Dataflow, Cloud Spanner, and Google’s machine learning offerings. These were all essential components of the exam, and without mastering them, I knew I wouldn’t be prepared.
After acknowledging my areas of weakness, I set out to create a structured study plan. I knew I couldn’t just dive into the most complex topics right away—first, I had to build a strong foundation. This meant revisiting core GCP concepts that I was already familiar with but may have overlooked. Revising the basics of networking, security, and data storage gave me a solid starting point and helped me better understand how these components interact within the larger GCP ecosystem.
Once I had revisited the basics, I started to tackle the more challenging areas. I dedicated specific weeks to focus on particular GCP tools and services, giving myself time to get comfortable with each. For example, one week was solely focused on Cloud Pub/Sub, where I studied its architecture, best practices, and use cases. The following week, I moved on to Dataflow, dedicating hours to understanding how to use it for data transformation and processing. This structured approach allowed me to dive deep into each area, without feeling rushed or overwhelmed.
It was also important to me to ensure that I was not only understanding the theoretical aspects of each service but also how to use them in real-world scenarios. The certification exam was designed to test practical skills, so I knew that hands-on practice was essential. As a result, I made sure to supplement my study plan with as much practical experience as possible. Whether it was setting up a pipeline in Dataflow, writing queries in BigQuery, or creating machine learning models in AI Platform, I was determined to practice until I felt confident in my ability to apply what I had learned in any scenario.
The exam covers a broad range of topics, from designing data systems to ensuring security and optimizing performance. As I worked through these topics, I found it crucial to constantly reinforce what I had learned by testing myself. Practice exams became an integral part of my preparation. They not only helped me gauge my progress but also allowed me to become familiar with the types of questions I would encounter on the actual exam.
Reflecting on my preparation journey, there are several key takeaways that helped me succeed in the Google Cloud Professional Data Engineer certification exam. First and foremost, the importance of a structured and strategic approach cannot be overstated. By breaking the study process into manageable chunks, focusing on one service or concept at a time, and reinforcing my knowledge with hands-on practice, I was able to steadily build my confidence.
The second critical lesson I learned was the value of hands-on experience. While theoretical knowledge is important, being able to apply that knowledge in real-world scenarios was crucial for passing the exam. The Google Cloud ecosystem is vast, and it’s easy to get lost in the details of each service. To counter this, I ensured that I spent significant time building and managing real data workflows in GCP. Whether it was designing a data pipeline, working with BigQuery for analytics, or deploying a machine learning model, the more I practiced, the more I solidified my understanding.
Another lesson learned was the need to stay updated on the latest developments in GCP. Google Cloud is a rapidly evolving platform, and new features are constantly being added to the services I studied. Staying informed about new tools and changes to existing ones was essential. I subscribed to Google Cloud newsletters, followed relevant blogs, and participated in online communities to keep up with the latest updates. This helped ensure that my knowledge was current and that I was aware of the newest best practices when taking the exam.
The exam is also focused heavily on performance optimization and cost management, two areas that can sometimes be overlooked in a practical work environment. However, understanding how to optimize GCP services for performance and cost is essential for passing the certification exam. These topics require a deeper level of thinking, as they force you to consider trade-offs between performance, cost, and scalability. As I studied, I spent time running various tests and comparing the costs and performance metrics of different services to gain a deeper understanding of how to balance these factors effectively.
Lastly, I learned the importance of staying disciplined and committed to the study plan. The exam is a test not just of knowledge, but of endurance. It can be easy to get discouraged or distracted, especially when faced with the vastness of the material. By sticking to my roadmap and setting aside dedicated time for study, I was able to stay focused and consistently make progress.
Achieving the Google Cloud Professional Data Engineer certification was a rewarding experience that required careful planning, hands-on practice, and the ability to continuously adapt to new information. By breaking down the exam material into manageable sections, practicing as much as possible, and staying updated on the latest developments in GCP, I was able to prepare effectively. For anyone looking to pursue this certification, I would emphasize the importance of staying disciplined, seeking hands-on practice, and fully immersing yourself in the Google Cloud ecosystem. With determination and the right approach, the Google Cloud Professional Data Engineer certification is an attainable goal that can open doors to new career opportunities and greater expertise in the field of cloud data engineering.
When preparing for a certification as demanding as the Google Cloud Professional Data Engineer exam, having a structured, methodical approach can make all the difference. For me, the process took place over the course of three focused weeks of study. I had to ensure that each day counted and that I spent ample time diving into the intricacies of Google Cloud, familiarizing myself with the platforms and tools that would be crucial for my success. Over the course of this three-week preparation, I was able to hone my understanding of key Google Cloud services, address gaps in my knowledge, and develop a strong foundation for tackling the exam questions. My journey through these three weeks was one of immersion, hands-on practice, and steady improvement, and I hope sharing this experience can help those who are preparing for the exam in the future.
The first week of my study plan was all about revisiting the core concepts of Google Cloud that I had already encountered in my previous experience as a Data Engineer. I began by working with tools I was most familiar with, such as BigQuery and DataFlow. This gave me the chance to reconnect with the concepts I had already mastered and ensure that I was comfortable with them. BigQuery, being one of the most important services for the exam, became a central focus during this time. I reviewed best practices for writing optimized SQL queries, explored data partitioning strategies, and solidified my knowledge of how to handle large datasets efficiently.
As I revisited these core concepts, I also began dedicating time to services that I wasn’t as familiar with, such as Bigtable and Dataproc. I had worked with these tools only sparingly in the past, but I quickly realized that they were integral to the exam. Bigtable, in particular, is an essential service for working with large, scalable data storage, and Dataproc is Google Cloud's managed Spark and Hadoop service, crucial for handling distributed data processing. I knew that understanding these services would be critical for succeeding in the exam, especially in areas related to storage, databases, and analytics.
The focus on these areas during Week 1 made it clear to me just how critical it would be to have a thorough understanding of data storage and management for the Google Cloud platform. These topics made up a significant portion of the exam, and getting comfortable with the underlying services was necessary to not only pass the test but also to be equipped for real-world data engineering tasks. As the days progressed, I incorporated more hands-on exercises, using the Google Cloud Console to interact directly with these tools. The more I practiced, the more I gained clarity on how these services interact with each other within Google Cloud’s larger ecosystem.
A key realization during Week 1 was the necessity of hands-on experience. While reviewing documentation and theory is important, there’s no substitute for applying your knowledge in real-world scenarios. I spent several hours building and testing sample data pipelines, exploring the various storage and processing options Google Cloud offers. By the end of Week 1, my practice test scores started to improve, and I felt more confident in my foundational understanding of GCP. However, I knew that the hardest challenges were still ahead, particularly in areas that were less familiar to me.
By Week 2, it was time to shift gears and focus on an area of GCP that I was less experienced with: Machine Learning (ML). It became clear to me that 35% of the exam would be dedicated to ML-related topics, making it an essential part of the preparation process. Despite my limited experience with machine learning at the start of my journey, I was determined to master the GCP-specific ML tools and concepts. I knew that this was a gap I needed to close if I was going to succeed in the exam.
The first step in my ML preparation was to dive deep into Google Cloud’s ML offerings, particularly services like AI Platform, AutoML, and TensorFlow on GCP. I made sure to understand the types of machine learning models supported by these services, as well as how to deploy and monitor them effectively. To ensure I fully grasped these concepts, I immersed myself in the official Google Cloud documentation and supplementary resources, such as online tutorials and courses. These resources were invaluable, as they provided structured guidance on how to approach the complexities of Google Cloud’s ML ecosystem.
Although I didn’t have prior hands-on experience with machine learning models, I adopted a "learning by doing" mindset. This approach led me to experiment with different ML use cases in Google Cloud, applying the tools in practice rather than just reading about them. I worked on building simple models using AI Platform, exploring the process from training the model to deploying it on Google Cloud for predictions. I also explored AutoML, which allows users with limited machine learning expertise to build custom models tailored to their specific datasets. Although my initial models weren’t perfect, the more I worked with these tools, the better I understood how they functioned and how they could be optimized for different business needs.
By the end of Week 2, I had a solid grasp on the core concepts and services related to machine learning within Google Cloud. My practice exams revealed that I had made significant strides in my understanding, as I was now able to answer questions related to model deployment, best practices for ML workflows, and optimizing model performance. Despite my initial lack of experience, my practical work with GCP’s ML services helped me gain the knowledge I needed to perform well in the exam’s ML section.
Looking back, Week 2 was a critical phase in my preparation. It showed me how important it is to approach learning with an open mind and a willingness to dive into new areas, even if they initially feel outside your comfort zone. While machine learning is a challenging topic, I realized that by tackling it head-on and practicing consistently, I was able to break down complex concepts and transform them into practical skills.
The final week of my study plan was when I really had to push myself to master the areas of Google Cloud that were less familiar to me. I had covered the basics of storage and machine learning, but there were still several critical components of the Google Cloud platform that I needed to grasp in order to feel fully prepared for the exam. Week 3 was dedicated to learning about compute, networking, and security, three areas where I had less direct experience but knew were crucial for the exam.
During this week, I approached these topics with a hands-on mindset. I didn’t just read about the services; I immediately integrated practice into my routine. For compute, I spent a significant amount of time understanding how to use Compute Engine, Google Kubernetes Engine (GKE), and App Engine to deploy scalable applications. I learned about containerization and how it fits into the larger context of Google Cloud’s offerings. GKE, for example, is a managed Kubernetes service that is essential for deploying containerized applications, and understanding it was key to understanding how to deploy applications at scale on Google Cloud.
Networking was another area where I had limited experience, but I knew it was vital for designing and securing data pipelines and other cloud-based solutions. In this area, I focused on virtual private cloud (VPC) configurations, load balancing, and networking best practices. I also worked on configuring Cloud VPN and Cloud Interconnect, which are critical for connecting on-premises infrastructure to Google Cloud. As I worked through these topics, I saw how compute and networking were closely linked, with networking being crucial for enabling communication between various GCP services.
The final piece of Week 3 was security. I focused on learning about identity and access management (IAM) in Google Cloud, encryption options, and security best practices for data protection. Understanding the security protocols and ensuring data protection within Google Cloud is an essential aspect of designing resilient and secure data systems. I also paid close attention to how security relates to compliance requirements and the ways Google Cloud services help organizations adhere to data protection regulations.
By the end of Week 3, I had gained a much deeper understanding of these topics and felt much more confident in my ability to apply them in practice. The exam included several scenarios that required me to design data pipelines and integrate multiple GCP services together, and I realized just how important it was to understand how these components worked in harmony. These scenarios also highlighted the need for architectural knowledge, as designing robust, scalable solutions required more than just theoretical understanding—it required a deep knowledge of how GCP services interact and how to configure them to meet specific business needs.
Looking back on my three-week preparation journey, the key takeaway was that success in the Google Cloud Professional Data Engineer exam wasn’t just about memorizing facts and learning tools—it was about integrating different GCP services and understanding how to apply them in real-world scenarios. While it was important to learn the individual services in isolation, the exam tested my ability to design solutions that leverage the full power of Google Cloud.
As the exam date approached, I could feel the pressure mounting. The Google Cloud Professional Data Engineer certification exam was not just a technical challenge—it was a test of endurance, focus, and strategy. I knew that to succeed, I had to be more than just knowledgeable about the Google Cloud ecosystem; I had to be strategic in how I approached the exam itself. The final week of preparation became a critical phase in refining my skills and ensuring that I was ready to tackle the test with confidence. It wasn’t just about revisiting the material I had studied but about simulating the exam experience, identifying gaps, and fine-tuning my approach.
By the time I entered the final stretch of my preparation, I had already spent weeks mastering Google Cloud tools, refining my knowledge of machine learning, and understanding the architecture of various services. But I knew that no amount of studying could fully prepare me for the exam without real practice. This realization led me to immerse myself in practice tests. I made it a priority to complete eight full-length practice exams before the actual exam. These tests weren’t just a means of gauging my readiness—they became a vital part of my strategy for mastering the test.
Each practice exam was designed to simulate the actual certification exam as closely as possible. This helped me become familiar with the types of questions I would face and the format of the exam. The more practice exams I completed, the more I recognized patterns in the types of questions asked and the areas that were frequently tested. For example, many of the questions revolved around optimizing performance and managing costs within Google Cloud services, so I dedicated extra time to ensure that I was comfortable with pricing models and the efficiency of different tools.
One of the key benefits of practice tests was their ability to help me refine my test-taking strategies. Early on, I realized that it wasn’t enough to simply know the material. I had to be strategic about how I approached each question. The timing of the exam became a critical factor—I had to ensure that I could answer the questions both quickly and accurately. In my early practice tests, I found myself lingering too long on certain questions, especially when I was unsure about the answer. This slowed me down, leaving me with less time for other questions. Recognizing this, I adjusted my approach by practicing with the timer set to simulate the real exam environment. This helped me get comfortable with answering questions within the time constraints, allowing me to manage my time more effectively on the actual exam day.
Completing multiple practice exams also helped me identify areas where I needed to improve. For example, I initially struggled with questions related to the inter-product connections within Google Cloud—how different services interacted with each other and how to design solutions that integrated multiple tools seamlessly. This was an area where I needed to strengthen my understanding, as the exam emphasized practical application and architectural knowledge. By consistently reviewing and practicing these areas, I was able to make significant improvements, boosting my confidence as the exam approached.
As the final days leading up to the exam ticked away, I shifted my focus toward reviewing the mistakes I had made in my practice tests. This was an essential part of the revision process because it allowed me to learn from my errors and adjust my strategies before the real exam. It became clear to me that mistakes were not something to be feared; they were opportunities to deepen my understanding.
I began by going through each practice test meticulously, paying special attention to the questions I had gotten wrong. For every incorrect answer, I made a note of the reasoning behind my mistake. Was it a lack of knowledge about the particular Google Cloud service, or was it an issue of misunderstanding how two services connected? Were there best practices or pricing models that I had overlooked? By analyzing each mistake in detail, I was able to identify patterns in my weak areas and gain insights into how to avoid similar mistakes in the future.
A significant portion of the exam focuses on best practices, and I realized that I had often made mistakes in areas where I hadn’t fully internalized these practices. Google Cloud offers a vast number of services, and each service comes with its own set of best practices for optimal performance, cost management, and scalability. Some of my errors were related to understanding these best practices—such as misapplying the appropriate storage class for a specific use case or not considering the trade-offs between performance and cost. By revisiting the official Google Cloud documentation and other reliable resources, I was able to reinforce these key principles and integrate them into my understanding.
One of the most impactful realizations came when I reviewed my mistakes related to pricing models. Pricing in the cloud is notoriously complex, and Google Cloud is no exception. There are various pricing models for different services, including pay-as-you-go, committed use contracts, and sustained use discounts. Many of the questions on the exam tested my ability to choose the most cost-effective option based on a particular scenario, and I had to be able to quickly calculate the cost of using certain services. In my practice tests, I had made several errors in this area because I hadn’t fully grasped the pricing structures of certain tools. After revisiting the pricing guides and practicing more scenarios, I was able to confidently handle these types of questions in the future.
As the days before the exam became more limited, I sought additional resources to help me quickly review and refresh my memory on key concepts. One of the best resources I found was the "Google Data Engineering Cheatsheet" by Maverick Lin, a concise yet thorough guide to the most important concepts and tools covered in the exam. This cheatsheet provided a quick overview of Google Cloud services, their functionalities, and the best practices associated with each. In the days leading up to the exam, this resource became my go-to for last-minute revisions. It allowed me to quickly review high-level topics without feeling overwhelmed, making it an essential tool in my final push for exam preparation.
Additionally, I turned to the "In a Minute" videos on Google Cloud Tech’s YouTube channel. These videos provided short, focused overviews of key Google Cloud services, including BigQuery, Pub/Sub, and Dataflow. Each video was designed to explain complex concepts in a simple and digestible manner, making them ideal for a quick refresh. As I watched these videos, I found that they helped me solidify my understanding of certain services and gave me a more intuitive grasp of how they could be applied in various scenarios.
These external resources, while not exhaustive, were extremely valuable in the final stages of my preparation. They allowed me to quickly fill in gaps in my knowledge and reinforce important concepts, particularly when I was pressed for time. By the time I sat down for the exam, I felt more confident and prepared, knowing that I had reviewed the core material and was ready to tackle the test.
As the day of the exam drew nearer, I realized that there was one final hurdle to overcome: managing the nerves and anxiety that often accompany high-stakes exams. Even though I had spent weeks preparing, there was still a lingering sense of uncertainty about how I would perform on the day of the test. The practice exams had been invaluable in helping me become comfortable with the format and timing, but I knew that the actual exam would still present challenges that I hadn’t yet encountered.
During my last round of practice tests, I focused not only on getting the answers right but also on managing my time effectively. Time management was one of the most critical aspects of the exam, as the clock was ticking down with every question. I found that pacing myself—answering the easy questions quickly, flagging the difficult ones for later, and taking a few seconds to review my answers—was the most effective approach. This allowed me to move through the questions with confidence and ensured that I didn’t waste time on questions I wasn’t immediately sure about.
In the final moments before the exam, I reminded myself of the hard work I had put into my preparation. The practice exams, the revision of mistakes, the external resources, and the test-taking strategies all came together to form a solid foundation for success. I had done everything I could to prepare, and now it was simply a matter of trusting in my knowledge and staying calm.
Reflecting on the entire preparation process, I can confidently say that the final week of practice and revision played a pivotal role in my success on the Google Cloud Professional Data Engineer certification exam. The combination of intensive practice tests, careful review of mistakes, and the strategic use of external resources helped me fine-tune my knowledge and approach. It was through this focused preparation that I was able to not only reinforce what I had learned but also develop the confidence and strategies needed to succeed.
For anyone preparing for the exam, I cannot stress enough how important practice and revision are. The exam requires more than just memorizing facts—it requires the ability to think critically, manage your time effectively, and apply your knowledge in real-world scenarios. By approaching your preparation with a clear strategy, refining your test-taking skills, and staying calm under pressure, you can ensure that you are ready to conquer the exam and achieve your certification goals.
Exam Day Insights – What to Expect and Final Tips
The day I had been preparing for had finally arrived. I woke up early with a mix of excitement and nervousness swirling inside me. All the hard work, weeks of studying, practice tests, and long hours of hands-on experience had led up to this moment. But as the time approached for me to sit down for the exam, I reminded myself that I had done the preparation. I had put in the time, learned the material, and equipped myself with the skills necessary to succeed. Now, it was simply a matter of trusting my preparation and taking the exam with confidence.
I made sure to stay calm and focused. Anxiety can cloud your thinking, and I knew that this could hinder my performance. I was aware that exams can be daunting, especially one as rigorous as the Google Cloud Professional Data Engineer exam, but I took a deep breath, reminded myself of my strengths, and steeled myself for what lay ahead. I knew that the exam would be challenging, but I was ready to face it head-on. The key was to stay composed, think critically, and avoid rushing through questions.
As I sat down for the exam, I quickly realized that the key to success was staying in the moment and not letting nerves take over. One of the most valuable pieces of advice I can give anyone taking this exam is to remain calm, especially when faced with difficult questions. It’s easy to panic when you come across a question that stumps you, but I learned early on that panicking only made things worse. If you find yourself stuck on a question, don’t hesitate to mark it for review and move on. Trust me, it’s far more beneficial to come back to it later when you’re in a more relaxed state of mind.
This tip became invaluable during my exam. I encountered a few questions that I wasn’t immediately sure about, and rather than letting them stress me out, I marked them for review and kept going. This approach helped me keep my mind clear and focused as I continued through the rest of the test. By the time I reached the end, I had enough time to go back and revisit those questions, and in many cases, I found that my initial instincts had been correct. The clarity I maintained throughout the exam was a result of trusting my knowledge and not allowing the pressure to derail me.
Another important strategy was to avoid overthinking the questions. It’s easy to get caught up in second-guessing yourself, especially when you're uncertain about the answer. I found that the more I overthought a question, the more confused I became. Instead, I made a conscious effort to trust my first instinct and move forward. Google Cloud is known for its practical, real-world applications, so the exam is designed to test your ability to apply what you’ve learned in real situations. I kept this in mind as I moved through the test, which helped me stay grounded and focused.
The test itself was designed in a way that felt familiar, reflecting the scenarios I had encountered during my preparation. As I worked through each question, I could see how the study material I had covered aligned with the challenges presented in the exam. From performance optimization to cost management and integrating different Google Cloud products, the exam mirrored the types of questions I had seen in practice tests. This was a comforting realization, as it confirmed that my preparation was on track and aligned with the actual exam’s focus.
When I finally clicked the submit button at the end of the exam, there was a mixture of relief and anticipation. The Google Cloud certification exam is intense, and completing it felt like a major accomplishment in itself. But what came next was even more rewarding—the result. In an instant, I saw the words "PASS" flash on the screen, and a wave of relief washed over me. All the stress and anxiety I had experienced during the weeks of preparation seemed to dissolve in that one moment of validation. I had done it.
The sense of pride that came with passing the exam was not just about the certification itself, but about the entire journey I had taken to get there. The countless hours spent studying, the practice exams, the late nights working through complex concepts—it all came together in that moment. I was proud of myself for sticking with it and for pushing through the challenges, both in terms of the exam content and the personal obstacles I had to overcome during my preparation.
Shortly after receiving the "PASS" notification, I was sent my official certificate, along with a voucher code for Google Cloud products. This was a nice bonus, adding a touch of value to the entire experience. The certificate itself felt like a tangible reminder of the hard work and dedication I had put into achieving this goal. More than just a credential, it symbolized the depth of knowledge I had gained about Google Cloud and the growth I had experienced as a data engineer.
Looking back on the entire journey, I realize that the Google Cloud Professional Data Engineer certification was much more than just a test of my knowledge—it was a transformative experience that reshaped how I view Google Cloud’s role in modern data engineering. Before I embarked on this certification journey, I had seen GCP as just another cloud platform—one among several that offered storage, compute, and machine learning services. But as I prepared for the exam, I began to appreciate the true power of GCP as a fully integrated ecosystem.
Through my preparation, I gained a deeper understanding of how Google Cloud offers more than just isolated services. It provides a seamless, interconnected platform that empowers data engineers to build comprehensive data pipelines, integrate real-time processing capabilities, and implement machine learning models with ease. I had previously been familiar with individual GCP tools, but this certification process showed me how these tools could be combined and applied in a holistic manner to solve real-world problems. The interconnected nature of Google Cloud’s offerings became one of the most valuable insights I gained during my preparation. It highlighted the importance of designing systems that work together efficiently rather than relying on individual components in isolation.
This newfound appreciation for GCP’s ecosystem has not only shaped my approach to the exam but also transformed my professional perspective on how cloud technologies can enable data-driven businesses. With the knowledge I gained during the preparation process, I now understand how to leverage Google Cloud to optimize data flows, reduce costs, and implement scalable solutions for a wide range of applications. It’s not just about storage or compute anymore—it’s about designing integrated, efficient systems that drive business outcomes.
One of the most important lessons I learned during this entire process is the significance of hands-on experience. While theory and documentation are essential for understanding concepts, they only take you so far. To truly grasp the complexities of Google Cloud, you must immerse yourself in practical work. This was a key realization as I moved through my preparation and is something I would emphasize to anyone considering this certification.
Practical experience is what solidifies your understanding and prepares you for real-world challenges. Throughout my preparation, I made sure to spend ample time working directly with GCP’s services. This allowed me to not only reinforce theoretical concepts but also gain the practical know-how required to apply them in real-life scenarios. The exam tests your ability to design, implement, and optimize data systems in Google Cloud, and the best way to prepare for this is through hands-on practice. This exposure to real-world challenges helped me develop a deeper understanding of the platform, and it became clear that this knowledge would be invaluable as I progressed in my career.
Hands-on experience also allows you to understand the nuances and limitations of each tool. For instance, I learned how different data storage options in GCP are optimized for specific use cases, and how performance can be impacted by the architecture of your solution. Understanding these details is crucial not just for passing the exam, but for becoming a more skilled and capable data engineer. The skills you acquire through practice are what ultimately set you apart in the field.
In conclusion, the journey to becoming a Google Cloud Professional Data Engineer is challenging but incredibly rewarding. It requires hard work, persistence, and a willingness to learn, adapt, and grow. The preparation process goes beyond just memorizing facts—it’s about developing a deeper understanding of Google Cloud’s services and how they can be applied to solve real-world problems. The certification is not just a credential; it’s a testament to your ability to design and implement effective data solutions in the cloud.
As I reflect on my journey, I realize that the lessons learned during this process have far-reaching implications for my career. The knowledge and skills gained during my preparation have empowered me to approach data engineering challenges with confidence and creativity. This certification has not only opened new doors for me professionally but has also reinforced my passion for data engineering and cloud technologies.
For anyone preparing for this certification, my advice is simple: stay committed, focus on hands-on practice, and embrace the learning journey. The effort you put in will pay off in ways that extend far beyond the exam.
As I look back on my experience preparing for the Google Cloud Professional Data Engineer exam, I realize that this journey was about much more than just passing an exam. It was about personal and professional growth, gaining a deeper understanding of Google Cloud’s vast ecosystem, and sharpening my skills as a data engineer. The exam itself served as a milestone, but the knowledge and experiences I gained throughout the process will continue to shape my career for years to come.
The certification process opened my eyes to the power of cloud technologies and how they can be harnessed to design scalable, efficient, and innovative data systems. Google Cloud is more than just a cloud provider; it’s a comprehensive ecosystem that enables professionals to solve complex data challenges. This realization has been transformative, not only in how I view cloud computing but also in how I approach data engineering as a whole.
As I reflect on the path I’ve taken to earn this certification, I am reminded of the importance of perseverance, hands-on experience, and a methodical approach to learning. The road to becoming a Google Cloud Professional Data Engineer was not without its challenges, but every step was worth it. The process has not only solidified my technical expertise but has also instilled in me a deeper appreciation for the power of cloud technologies in shaping the future of data-driven businesses.
If you're embarking on the same journey, my advice is to embrace the challenge, stay focused, and trust in your ability to succeed. The skills you develop along the way will serve you well, both in the exam and in your career as a data engineer. The effort you put into mastering Google Cloud will pay off in ways that extend far beyond the certification itself, enriching your professional life and empowering you to make a lasting impact in the world of data engineering.
Go to testing centre with ease on our mind when you use Google Professional Data Engineer vce exam dumps, practice test questions and answers. Google Professional Data Engineer Professional Data Engineer on Google Cloud Platform certification practice test questions and answers, study guide, exam dumps and video training course in vce format to help you study with ease. Prepare with confidence and study using Google Professional Data Engineer exam dumps & practice test questions and answers vce from ExamCollection.
Purchase Individually


Google Professional Data Engineer Video Course

Top Google Certifications

















Top Google Certification Exams
Site Search:

SPECIAL OFFER: GET 10% OFF

Pass your Exam with ExamCollection's PREMIUM files!
SPECIAL OFFER: GET 10% OFF
Use Discount Code:
MIN10OFF
A confirmation link was sent to your e-mail.
Please check your mailbox for a message from support@examcollection.com and follow the directions.

Download Free Demo of VCE Exam Simulator
Experience Avanset VCE Exam Simulator for yourself.
Simply submit your e-mail address below to get started with our interactive software demo of your free trial.
simply put, I wouldn’t have made it without these Professional Data Engineer questions and answers… I realized just days before the exam that I needed to do so much in order to pass this test… and these materials helped me just even though i had so little time! Am very grateful to ExamCollection!
@gavin, these google professional data engineer vce files will certainly be of great help in your exam but i wouldn’t advise you to shut out other learning materials… it is wiser to combine varied resources which will make sure you don’t struggle at all during the exam. wish you luck☺
will the braindumps for Professional Data Engineer exam be enough to get ready for this test?? am using them to prepare and so far they seem okay to me but want to hear some advice from those who already passed the exam…
Guys, I have some advice for candidates… using these Professional Data Engineer practice tests can save you a great deal of time and still be very effective . they saved me just when I thought I was out of time… thumbs up ExamCollection for this superb materials and for providing this treasure just for free!
@jace, i used several materials but can surely say that i aced this test thanks to these dumps for Professional Data Engineer exam… they helped me build strength in all the required areas so the exam was easy for me. their level of validity is commendable! you should go for these braindumps if you want to score high, they will help you too!
anyone who has passed this exam recently? did you use these Google Professional Data Engineer exam dumps? if yes to what extend were they helpful?
Hi,
Need help to get practice exam for google data engineer.
Tnx.
Please can you tell me where I can find the download. Many thanks.
Need it urgently.