


Premium File
72 Q&A
$76.99$69.99
EMC E20-807 Exam Questions & Answers, Accurate & Verified By IT Experts
Instant Download, Free Fast Updates, 99.6% Pass Rate
72 Questions & Answers
Last Update: Jun 08, 2026
$69.99
EMC E20-807 Exam Screenshots
EMC E20-807 Practice Test Questions, Exam Dumps
EMC E20-807 (VMAX3 Solutions Expert Exam) exam dumps vce, practice test questions, study guide & video training course to study and pass quickly and easily. EMC E20-807 VMAX3 Solutions Expert Exam exam dumps & practice test questions and answers. You need avanset vce exam simulator in order to study the EMC E20-807 certification exam dumps & EMC E20-807 practice test questions in vce format.
The E20-807 Expert - VMAX All Flash and VMAX3 Solutions Exam is a credential designed for technology professionals who are tasked with the implementation and management of advanced storage solutions. This certification validates an individual's ability to handle complex tasks within VMAX environments, including configuration, replication, performance management, and security. Passing this exam signifies a deep understanding of the platform's architecture and its extensive feature set. Preparation for the E20-807 Exam requires a comprehensive grasp of both theoretical knowledge and practical application skills related to these high-end enterprise storage arrays.
This series will serve as a detailed guide, breaking down the critical knowledge areas required to successfully challenge the E20-807 Exam. We will explore the fundamental architecture, storage provisioning, local and remote replication technologies, performance monitoring, and advanced features. Each part is designed to build upon the last, providing a structured learning path for candidates. The goal is to equip you with the in-depth information needed to not only pass the certification but also to excel in your role as a VMAX solutions expert. This initial part focuses on the foundational building blocks of the VMAX platform.
Achieving the expert-level certification validated by the E20-807 Exam is a significant milestone for any storage professional. It demonstrates a superior level of competence in managing one of the industry's leading enterprise storage platforms. This credential can enhance career opportunities, opening doors to senior roles such as storage architect, implementation specialist, or senior systems administrator. It serves as proof to employers and clients that an individual possesses the requisite skills to design, deploy, and maintain mission-critical storage infrastructures, ensuring high levels of availability, performance, and data protection for essential business applications.
Furthermore, the process of studying for the E20-807 Exam itself is incredibly valuable. It forces a deep dive into the intricacies of VMAX architecture, from the HYPERMAX operating system to its sophisticated data services. This rigorous preparation builds a holistic understanding that transcends simple day-to-day tasks. It fosters problem-solving skills and the ability to optimize the storage environment for maximum efficiency and return on investment. The knowledge gained is directly applicable to real-world scenarios, making certified professionals a significant asset to any organization that relies on these powerful storage systems.
The VMAX3 family of arrays represents a significant architectural evolution, centered around the dynamic virtual matrix. This design moves away from the traditional monolithic structure to a more scalable and agile framework. At its heart is the HYPERMAX operating system, which is a purpose-built OS designed for the high-demand world of enterprise storage. It abstracts the underlying hardware resources and presents them as a unified pool, allowing for dynamic allocation and management. A key objective for any candidate of the E20-807 Exam is to fully understand how these architectural components interact to deliver performance and resilience.
The physical building blocks of a VMAX3 system are the engines. Each engine contains director boards, which house front-end, back-end, and global memory components. The directors are interconnected through the dynamic virtual matrix interconnect, a high-speed, redundant network that enables seamless communication and data transfer between all components in the array. This architecture allows the system to scale out by adding more engines, linearly increasing performance and capacity. Understanding this scale-out model is crucial for answering questions on the E20-807 Exam related to system growth and performance planning.
Global memory is a critical component, acting as a shared cache for the entire array. It is physically distributed across all the directors in the system but functions as a single, logical cache pool. This design ensures extremely low-latency access to data for all host applications connected to the array. The efficiency of the caching algorithms and the way data is protected within global memory are important topics. The E20-807 Exam will likely test your knowledge of how write operations are acknowledged and de-staged to persistent disk storage, a process that relies heavily on the integrity and performance of the global memory.
The HYPERMAX operating system is the software foundation of VMAX3 and VMAX All Flash arrays. It is a purpose-built, real-time OS that manages all the hardware resources and data services of the system. One of its key innovations is the ability to run integrated data services directly on the array, co-resident with the core storage functions. This is accomplished through a containerized architecture, where services like embedded NAS (eNAS) or embedded management can run in their own secure, isolated environments without impacting storage performance. The E20-807 Exam requires a clear understanding of this software architecture.
Another fundamental feature of HYPERMAX OS that is critical for the E20-807 Exam is its approach to resource allocation. The operating system virtualizes all the underlying CPU cores, memory, and connectivity, presenting them as a single pool. This allows for the dynamic distribution of resources to where they are needed most. For example, if a specific application requires more processing power for data reduction, HYPERMAX OS can allocate additional CPU cycles to that task in real-time. This agility is a core tenet of the VMAX3 design and is essential for maintaining performance under varied and unpredictable workloads.
The concept of Service Level Objectives (SLOs) is directly managed by the HYPERMAX OS. Instead of manually configuring complex parameters like RAID types and disk layouts, administrators simply assign an SLO (such as Diamond, Platinum, or Gold) to an application's storage group. The OS then automates the entire back-end placement and data management process to ensure the performance targets of that SLO are met. This radical simplification of storage management is a major topic, and a deep understanding of how HYPERMAX OS enforces these policies is absolutely necessary for success on the E20-807 Exam.
The Dynamic Virtual Matrix is the interconnect technology that links all the VMAX engines together. It is not a single, physical backplane but rather a set of high-speed, redundant network links that create a powerful any-to-any communication fabric. This allows any director on any engine to communicate directly with any other director in the array with minimal latency. This architecture is fundamental to the scalability and high availability of the VMAX platform. It eliminates the bottlenecks that can occur in more traditional, centrally switched storage architectures.
For the E20-807 Exam, you must grasp how the virtual matrix enables both scale-up and scale-out capabilities. A system can be scaled up by adding more processing power and memory within existing engines, and it can be scaled out by adding entirely new engines to the matrix. The interconnect seamlessly integrates new resources, automatically expanding the pool of available cache, CPU, and port connectivity. This process is non-disruptive, allowing organizations to grow their storage infrastructure in line with business demands without requiring downtime, a key feature tested in the exam.
Redundancy is built into every layer of the Dynamic Virtual Matrix. There are multiple, physically separate fabrics for communication, ensuring that the failure of a single link or even an entire interconnect switch does not impact the overall operation of the array. The HYPERMAX OS constantly monitors the health of the interconnect and can instantly reroute traffic in the event of a component failure. This intrinsic fault tolerance is a hallmark of the VMAX design and a critical knowledge area for any professional preparing for the E20-807 Exam.
While sharing the same HYPERMAX OS and Dynamic Virtual Matrix architecture as the VMAX3, the VMAX All Flash family is specifically engineered and optimized for solid-state drives. These systems are designed to deliver consistent, predictable, and extreme performance with sub-millisecond latencies. A key differentiator is the V-Brick packaging. A V-Brick is a single engine that includes the necessary processing power, memory, and a set base capacity of flash storage. The system scales by adding additional V-Bricks, simplifying the process of quoting, ordering, and expansion.
The E20-807 Exam will expect candidates to understand the features that are particularly important in an all-flash context. This includes inline data reduction technologies. VMAX All Flash provides both inline compression and deduplication to significantly increase the effective storage capacity. Understanding how these features work, their performance impact, and how to manage them is crucial. For instance, you should know that compression is applied to all new writes and is designed to be extremely efficient, adding minimal latency to the I/O path.
Another important aspect is the write-folding mechanism, which is optimized for flash media. This technique helps to minimize write amplification, a phenomenon that can reduce the endurance and lifespan of SSDs. By coalescing multiple small, random writes in cache before writing them to flash as a single, large sequential write, the system improves both performance and the longevity of the media. These flash-specific optimizations are a key part of the VMAX All Flash value proposition and are therefore essential knowledge for the E20-807 Exam.
Storage provisioning on a VMAX array is the process of carving out logical units of storage (LUNs) from the overall capacity pool and presenting them to host servers. The E20-807 Exam covers this process in detail, from the creation of data devices to the final masking and presentation to a host. The primary method for provisioning is thin provisioning. Thin devices, or TDEVs, are logical constructs that have no physical capacity allocated to them initially. Capacity is only drawn from a shared thin pool as the host application writes data for the first time.
This on-demand allocation model provides significant benefits in terms of storage efficiency. Administrators can provision large amounts of logical capacity to applications without having to purchase and allocate all the physical disk space upfront. This "thin-on-thin" approach is the standard for VMAX3 and VMAX All Flash. Understanding the relationship between thin devices, the thin pools they draw capacity from, and the underlying data pool is fundamental. The E20-807 Exam will test your knowledge of how to create, manage, and monitor these constructs using tools like Unisphere.
The process involves several steps. First, physical disks are grouped into data pools. A thin pool is then created on top of this data pool. Next, one or more thin devices (LUNs) are created and associated with that thin pool. These devices are then placed into a storage group, which represents a specific application or server. Finally, the storage group is associated with a port group (the front-end array ports) and an initiator group (the host's WWNs or iSCSI names) within a masking view. This masking view acts as the final access control, making the storage visible only to the intended host.
Service Level Objectives, or SLOs, are a cornerstone of management on VMAX3 and VMAX All Flash platforms. This feature fundamentally changes the paradigm of performance management. Instead of manually selecting RAID types, disk speeds, and data layouts, an administrator simply chooses a predefined performance policy for an application. The system then automates all the back-end work to ensure that the storage provided meets the performance characteristics of that policy. A comprehensive understanding of this concept is non-negotiable for the E20-807 Exam.
The VMAX platform offers several SLO tiers, such as Diamond, Platinum, Gold, Silver, and Bronze. Each tier is associated with a specific average response time target. For example, Diamond is designed for the most mission-critical workloads, offering the lowest possible latency, typically sub-millisecond. As you move down the tiers to Platinum, Gold, and so on, the response time targets become slightly higher, catering to applications with less stringent performance requirements. The E20-807 Exam will test your ability to match application workloads to the appropriate SLO.
When an SLO is assigned to a storage group, the HYPERMAX operating system intelligently places the data across the available media to meet the performance goal. For Diamond SLOs, this means prioritizing the fastest flash tiers and ensuring the data receives preferential treatment within the system's cache and processing queues. The system constantly monitors the performance of the workload. If it detects that the response times are not meeting the SLO target, it can automatically and non-disruptively move data to a faster tier of storage to remediate the issue. This dynamic optimization is a key feature to master.
The concept of a "workload planner" is also tied to SLOs. This tool allows administrators to model the impact of adding new workloads to the array. By specifying the capacity and the desired SLO for a new application, the planner can analyze the existing resource utilization and predict whether the array can meet the new performance demands without negatively affecting existing workloads. This proactive planning capability is a significant management benefit, and questions related to its use are fair game for the E20-807 Exam. It helps in making informed decisions about capacity and performance scaling.
Unisphere for VMAX is the primary graphical user interface (GUI) for managing VMAX3 and VMAX All Flash arrays. It provides a centralized, web-based console for performing nearly all administrative tasks, from provisioning and replication to performance monitoring and reporting. The interface is designed to be intuitive, with dashboards that provide an at-a-glance view of system health, capacity utilization, and performance metrics. Familiarity with the Unisphere interface, its navigation, and its core workflows is absolutely essential for anyone preparing for the E20-807 Exam.
One of the most powerful aspects of Unisphere is its focus on SLO-based provisioning. The provisioning wizards are designed around the concept of service levels. An administrator can provision storage for a new application in just a few clicks by defining the host, the capacity required, and the desired SLO. Unisphere handles the creation of the storage group, thin devices, and the masking view in the background. This simplified, application-centric workflow dramatically reduces the administrative overhead and potential for human error. You should be comfortable navigating these wizards.
Performance management is another critical function within Unisphere. The tool provides detailed, real-time, and historical performance charts for every component of the array, from front-end directors down to individual storage LUNs. Administrators can diagnose performance issues by analyzing metrics like IOPS, throughput, and response times. The platform allows for the creation of customized dashboards and reports to track key performance indicators over time. The E20-807 Exam will expect you to know how to use Unisphere to identify performance bottlenecks and validate that SLOs are being met.
Unisphere also serves as the control plane for advanced data services. Setting up local replication with TimeFinder SnapVX or remote replication with SRDF is managed through dedicated wizards and dashboards within the interface. These sections provide a clear view of replication sessions, their status, and the health of the underlying infrastructure. The ability to perform common replication operations, such as creating a snapshot, failing over to a remote site, or splitting a replica, using the Unisphere GUI is a practical skill that is directly relevant to the E20-807 Exam.
While Unisphere provides a powerful GUI, Solutions Enabler offers a robust command-line interface (CLI) for managing VMAX arrays. The CLI is favored by many experienced administrators for its speed, efficiency, and scriptability. Nearly every function available in Unisphere can also be performed using Solutions Enabler commands. For the E20-807 Exam, you must have a solid understanding of the CLI's syntax and be familiar with the key command sets for common administrative tasks. This includes provisioning, replication, and system monitoring.
The core of Solutions Enabler is a set of daemons that run on a management host and communicate with the VMAX array. The primary command used to interact with the system is symcli. This command is followed by a series of verbs and options to specify the desired action. For example, commands like symdev, symcfg, symaccess, and symsg are used for managing devices, configuration, access control, and storage groups, respectively. Knowing which command family to use for a specific task is a fundamental requirement.
Automation is a key advantage of using the CLI. Solutions Enabler commands can be easily incorporated into scripts to automate repetitive tasks. This is incredibly powerful for large environments or for service providers who need to provision and manage storage for many different tenants. For instance, a script could be written to provision a new server completely, including creating devices, adding them to a storage group, and creating the masking view. The E20-807 Exam may present scenarios where scripting or automation is the most logical solution.
Beyond basic management, Solutions Enabler is also critical for advanced operations and troubleshooting. Certain detailed diagnostic information and configuration options may only be accessible through the CLI. It is also the primary interface for managing TimeFinder and SRDF operations in complex, scripted disaster recovery scenarios. While the GUI is excellent for visualization, the CLI provides the granular control and scriptability needed for sophisticated automation and orchestration. A well-rounded VMAX expert, and thus a successful E20-807 Exam candidate, must be proficient in both Unisphere and Solutions Enabler.
While the basics of thin provisioning are straightforward, the E20-807 Exam requires a deeper understanding of its more advanced aspects. One such concept is thin pool management. A thin pool has warning thresholds that can be configured to alert administrators when the pool's utilization reaches a certain percentage, for example, 80%. This proactive alerting is crucial to prevent an out-of-space condition, which could cause write failures for all applications using that pool. Knowing how to set and respond to these alerts is a key operational skill.
Another important topic is space reclamation. In a virtualized server environment, when a virtual machine is deleted or data is removed from within a guest operating system, the storage array is not automatically aware that this space can be freed. This requires the use of commands like UNMAP (for SCSI) or TRIM (for ATA). The E20-807 Exam will expect you to understand how the VMAX array supports these commands to reclaim unused blocks within a thin pool. This process is vital for maintaining the long-term efficiency of thin provisioning.
The concept of data reduction is tightly integrated with thin provisioning on VMAX All Flash arrays. Inline compression and deduplication work to reduce the amount of physical space consumed by the data written to a thin pool. This means that a thin pool with a physical capacity of 100TB might be able to store 300TB or more of logical application data. Understanding how these data reduction ratios are reported and how they affect capacity planning is critical. The exam may present scenarios where you need to calculate effective capacity based on expected reduction rates.
Finally, you should understand the performance characteristics of thin devices. While modern VMAX arrays are designed to provide excellent performance for thin-provisioned LUNs, there are still design considerations. The layout of the data pool that backs the thin pool can have an impact. The system uses advanced algorithms to distribute allocations across all the physical media in the data pool to avoid hotspots. Grasping this underlying mechanism and how it contributes to consistent performance, even in a highly shared environment, demonstrates the level of expertise required for the E20-807 Exam.
Data reduction is a critical feature of VMAX All Flash systems, designed to maximize the effective capacity of the array. The E20-807 Exam requires a detailed understanding of the different data reduction methods employed and how they work. The primary method is inline compression. This process occurs in real-time as data is written from the host, before it is committed to flash storage. The VMAX uses a highly efficient and hardware-accelerated compression algorithm that is designed to have a negligible impact on write latency.
The compression engine analyzes incoming blocks of data and applies a lossless algorithm to reduce their size. This process is granular, meaning that if a block of data is not compressible, it is simply written in its original form without penalty. The feature is enabled on a per-storage-group basis, giving administrators the flexibility to use it only for workloads that are likely to benefit. Understanding how to enable, disable, and monitor the effectiveness of compression for different applications is a key skill.
In addition to compression, VMAX All Flash arrays also offer deduplication, although its implementation and use case can be more specific. Deduplication works by identifying and eliminating redundant copies of data blocks. While inline compression works on the data within a single I/O, deduplication looks for duplicate blocks across a wider storage pool. This feature can provide significant capacity savings for workloads with high levels of data redundancy, such as virtual desktop infrastructure (VDI) or full-copy databases.
It is important for the E20-807 Exam to know that these data reduction features are fully integrated with other VMAX data services. For example, data remains in its reduced form when it is replicated using SRDF or snapshotted using SnapVX. This means that the capacity savings are carried over to the disaster recovery site and to the snapshot copies, reducing the overall storage footprint across the entire infrastructure. This synergy between data services is a powerful aspect of the VMAX platform.
Local replication is a fundamental pillar of any comprehensive data protection strategy. It involves creating copies of data within the same storage array, providing a rapid and efficient way to recover from a wide range of common data corruption events. These events can include software bugs, virus attacks, or accidental user errors, such as deleting a critical file or database table. For the E20-807 Exam, understanding the business case for local replication is as important as knowing the technical implementation. The primary goal is to minimize the recovery point objective (RPO) and recovery time objective (RTO) for logical corruptions.
Unlike remote replication, which protects against a full site disaster, local replication is optimized for operational recovery. The copies, known as snapshots, are stored on the same array as the source data, allowing for near-instantaneous access and recovery. A database administrator, for example, could use a snapshot taken just minutes before a failed batch job to instantly revert the database to a known good state, dramatically reducing application downtime. This speed is a key differentiator from traditional backup-to-tape methods which can take hours to restore.
TimeFinder SnapVX is the local replication solution for VMAX3 and VMAX All Flash arrays. It is a highly efficient, space-saving snapshot technology that is a major focus of the E20-807 Exam. It allows for the creation of up to 256 snapshots per source device with minimal performance impact on the production application. These snapshots are pointer-based, meaning they consume no physical capacity when they are first created. Space is only consumed from a shared pool when the source data is changed, a concept known as redirect-on-write.
Understanding the various use cases for local replication is crucial for the exam. Beyond simple data recovery, snapshots are widely used for non-disruptive backups. A backup server can mount a snapshot of a production database to perform a full backup without ever impacting the live application. Snapshots are also invaluable for development and testing, allowing teams to work with recent, realistic copies of production data in an isolated environment without the need to provision duplicate storage. A VMAX expert must be able to articulate and implement these different use cases.
TimeFinder SnapVX represents a significant evolution of snapshot technology on the VMAX platform. It was designed from the ground up for the HYPERMAX operating system to be more scalable, efficient, and easier to manage than its predecessors. The E20-807 Exam will test your in-depth knowledge of its architecture and operation. A key departure from older TimeFinder versions is the elimination of the need to pre-configure target devices. With SnapVX, there is no concept of a "copy session" in the traditional sense. A snapshot is simply a point-in-time image of a source device.
When a snapshot is created for a storage group, SnapVX creates a set of pointers that reference the exact state of the source devices at that moment. The snapshot itself has a name and a generation number. For example, you could create a daily snapshot named "DailyBackup" and the system would automatically manage the generations for each day. This makes managing recurring snapshots simple and intuitive. The system can retain up to 256 snapshots per source device, providing a high degree of granularity for recovery points.
One of the most important architectural features to understand for the E20-807 Exam is how SnapVX handles changes. It uses a redirect-on-write mechanism. When a write comes to a source device that has snapshots, the array does not overwrite the original block of data. Instead, it writes the new data to a new location within the thin pool and updates the source device's pointers to reference the new block. The original block is preserved for the snapshot. This method is extremely efficient and avoids the performance penalty associated with traditional copy-on-write snapshots.
The capacity used by SnapVX snapshots is drawn from the same thin pool as the source devices. This shared capacity model simplifies management as there is no need to create separate, dedicated pools for snapshot delta storage. However, it also means that capacity must be monitored carefully. The E20-807 Exam will expect you to know how to monitor snapshot space usage and plan for the capacity required to meet data retention policies. SnapVX provides detailed reporting on how much space each snapshot is consuming, which is essential for effective capacity management.
While SnapVX snapshots are initially just pointer-based images, they need to be made accessible to a host for recovery or other purposes. This is achieved by linking the snapshot to a target volume. A target volume is a standard thin device that has been provisioned but contains no data. The process of linking effectively presents the point-in-time image of the snapshot through the target LUN. This target LUN can then be masked and mounted to a host, which will see the data exactly as it existed when the snapshot was taken.
The linking process is a critical operation that you must understand for the E20-807 Exam. A single snapshot can be linked to multiple target devices simultaneously, allowing different hosts to access the same point-in-time data. This is useful for parallel processing or for providing copies to multiple development teams. The links can be created in either a no-copy or a copy mode. In the default no-copy mode, the target is a space-saving, pointer-based view of the snapshot. In copy mode, a full-copy background process is initiated to copy all the data from the snapshot to the target device.
Unlinking a target from a snapshot is the process that removes the host's access to the point-in-time data. Once the last link to a snapshot is removed, the snapshot reverts to being a background pointer-based image. The snapshot itself is not deleted until an explicit termination command is issued. This separation of the link/unlink and create/terminate operations provides a high degree of flexibility. You can grant and revoke access to a point-in-time copy without affecting the integrity of the snapshot itself.
The management of these operations can be performed through both Unisphere for VMAX and the Solutions Enabler CLI. The exam will expect you to be familiar with the commands and wizard steps for creating a snapshot, linking it to a target, presenting the target to a host, and then unlinking and terminating the snapshot when it is no longer needed. Understanding the lifecycle of a snapshot, from creation to termination, including the linking phase, is a core competency for a VMAX expert.
Beyond the basic create, link, and terminate operations, SnapVX offers several advanced features that are important for the E20-807 Exam. One such feature is the ability to restore data directly from a snapshot back to the source volume. This operation is extremely fast and efficient. It is accomplished by essentially changing the source device's pointers to reference the data blocks from the snapshot, effectively reverting the volume to its previous state. This is much faster than performing a host-based file copy from a linked target.
Another powerful capability is the concept of snapshot deltas. You can compare two different snapshots of the same source device and generate a list of the tracks that have changed between those two points in time. This is useful for incremental backup applications or for understanding what changes occurred during a specific window. This functionality provides insight into the rate of change of an application's data, which can be valuable for capacity planning and troubleshooting.
SnapVX is also deeply integrated with remote replication. You can take a snapshot of a device that is being replicated by SRDF. This can be done on either the source (R1) or the target (R2) side of the SRDF pair. Taking snapshots of the R2 device is a common strategy for creating backup and test copies at the disaster recovery site without impacting the production array. The E20-807 Exam may present complex scenarios involving the interaction between SnapVX and SRDF, and you must understand the rules and best practices for these integrated solutions.
Finally, managing snapshot retention policies is a key operational task. While you can manually create and terminate snapshots, most environments use automated scripts or scheduling software to manage this process. For example, a script might run every hour to create a new snapshot and terminate the snapshot that is now more than 24 hours old. While the VMAX array itself does not have a built-in scheduler for snapshots, understanding how to automate these recurring tasks using external tools and the Solutions Enabler CLI is a practical skill expected of a certified expert.
To successfully pass the E20-807 Exam, you need to understand the best practices for implementing TimeFinder SnapVX in a production environment. A primary consideration is capacity management for the SRP, the underlying capacity pool for both source LUNs and snapshot deltas. Because new writes are redirected, the SRP must have sufficient free space to accommodate both new host writes and the preservation of original blocks for snapshots. Monitoring SRP utilization and setting appropriate alerts are critical operational disciplines.
Performance is another key consideration. While the redirect-on-write architecture of SnapVX is highly efficient, there can still be a minor performance impact on write-intensive workloads, particularly if there are a large number of snapshots being retained. This is because the system has more metadata to manage. For most workloads, this impact is negligible, but for extreme performance applications, it is a factor to be aware of. The E20-807 Exam will expect you to understand the architectural reasons for any potential performance overhead.
When designing a local replication strategy, it is important to align the frequency and retention of snapshots with the business requirements for recovery. Creating snapshots every five minutes might be necessary for a critical database, but it would be excessive for less critical file server data. A well-designed policy balances the need for granular recovery points against the capacity consumption and management overhead of retaining a large number of snapshots. This ability to translate business requirements into a technical solution is a hallmark of an expert.
Finally, regular testing of the recovery process is a crucial best practice. It is not enough to simply create snapshots; you must periodically validate that you can successfully link them and recover data. This can involve mounting a snapshot to a test server and verifying the integrity of the files or database. Documenting the recovery procedure and testing it ensures that when a real data corruption event occurs, the recovery process will be fast, efficient, and successful. The E20-807 Exam emphasizes the practical application of these technologies, including disaster recovery and business continuity planning.
Disaster recovery is a critical component of business continuity, focused on restoring IT operations at a secondary site after a primary site has been rendered inoperable by a catastrophic event. This could be a natural disaster like a flood or earthquake, a widespread power outage, or a severe security breach. The goal of a disaster recovery solution is to protect against a total site failure. For the E20-807 Exam, you must understand that this is distinct from local replication, which protects against logical data corruption. Disaster recovery is about geographical separation and survivability.
The two most important metrics in disaster recovery are the Recovery Point Objective (RPO) and the Recovery Time Objective (RTO). RPO defines the maximum amount of data loss that a business can tolerate, measured in time. An RPO of zero means no data loss is acceptable. RTO defines the maximum amount of time allowed to bring critical applications back online after a disaster is declared. A successful E20-807 Exam candidate must be able to design a solution that meets specific RPO and RTO requirements dictated by the business.
Symmetrix Remote Data Facility, or SRDF, is the gold standard for remote replication in the enterprise storage industry and the key technology for providing disaster recovery on the VMAX platform. It is a family of products that provides robust, trusted replication of data between two or more VMAX arrays located in different geographical locations. SRDF operates at the array level, making it independent of the host operating system, file system, or database. This application transparency is one of its key strengths.
A deep and thorough understanding of the entire SRDF family is arguably one of the most important knowledge domains for the E20-807 Exam. This includes not just the different modes of operation, but also the management of SRDF pairs, the network requirements, and the procedures for performing failover and failback operations. The exam will present complex scenarios that test your ability to configure, manage, and troubleshoot SRDF in a variety of business continuity situations. Mastering SRDF is essential for achieving the expert-level certification.
SRDF Synchronous mode, or SRDF/S, offers a zero data loss disaster recovery solution. It is designed for mission-critical applications where data integrity is paramount and any amount of data loss is unacceptable. This corresponds to a Recovery Point Objective (RPO) of zero. For the E20-807 Exam, you must understand the exact write I/O sequence for SRDF/S. When a host sends a write to the primary array (known as the R1), the VMAX does not acknowledge the write back to the host until that same write has been successfully transmitted and committed to the cache of the secondary array (the R2).
This lock-step process guarantees that the R1 and R2 devices are always identical, mirror images of each other. If a disaster were to strike the primary site, the secondary site would have an exact, up-to-the-millisecond copy of the data, ready to be brought online. This zero RPO comes with a performance consideration. The latency of the network link between the two arrays directly impacts the application's write response time. Every write operation must incur a round-trip delay over the SRDF network link.
Because of this performance dependency, SRDF/S is typically deployed in metropolitan area distances, usually less than 200 kilometers or 120 miles apart, where dedicated, low-latency network connections are available. The E20-807 Exam will expect you to know the practical distance limitations and network bandwidth requirements for implementing a successful SRDF/S solution. You should be able to calculate the bandwidth needed to support a given workload and understand the impact of latency on application performance.
Managing SRDF/S pairs involves operations such as establishing the initial synchronization, splitting the pairs for testing, and failing over in a disaster scenario. These operations are managed through Solutions Enabler CLI commands (like symrdf) or the Unisphere for VMAX GUI. A key concept is the state of the SRDF pair, such as Synchronized, Split, or Failed Over. Understanding what each state means and how to transition between them is a fundamental skill that will be tested on the E20-807 Exam.
SRDF Asynchronous mode, or SRDF/A, is designed for disaster recovery over extended distances where synchronous replication is not feasible due to network latency. It provides a near-zero RPO solution while decoupling application write performance from the network. In SRDF/A, when a host sends a write to the R1 array, the array acknowledges the write immediately back to the host after it is committed to local cache. The data is then transmitted to the R2 array in the background. The E20-807 Exam requires a precise understanding of this mechanism.
To maintain data consistency, SRDF/A collects multiple writes from the application into a "delta set" in the R1 cache. This entire collection of dependent writes is then transmitted to the R2 array as a single, consistent group. This ensures that the R2 site never has a partially completed transaction, which is critical for database applications. The RPO in an SRDF/A environment is typically measured in seconds, representing the time it takes to fill a delta set and transmit it across the link. For most applications, this minimal data exposure is an acceptable trade-off for intercontinental distance protection.
A key component of SRDF/A is the concept of cache utilization. The R1 array's cache is used to buffer the delta sets before they are sent to the R2. Sufficient cache and network bandwidth must be available to handle the application's peak write rate. If the network link becomes congested or the R2 array cannot keep up, the R1 cache will begin to fill. SRDF/A has sophisticated mechanisms to manage this, but a prolonged outage can impact R1 performance. The E20-807 Exam will test your knowledge of how to size and monitor the resources required for SRDF/A.
Managing SRDF/A is similar to SRDF/S, using the same tools, but the states and behaviors are different. For example, during normal operation, the R2 devices will be slightly behind the R1, but they are always in a transactionally consistent state. Performing a failover with SRDF/A involves activating the R2 devices, which brings them online with the last successfully transmitted delta set. Understanding the failover process and the potential for a small amount of data loss is a critical distinction that you must grasp for the E20-807 Exam.
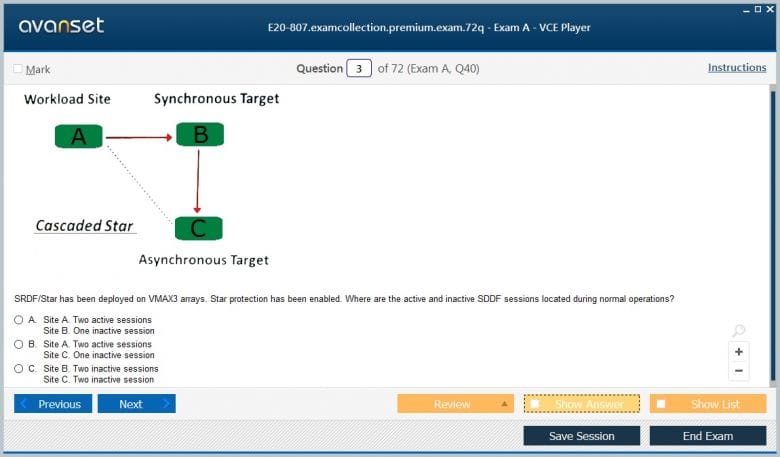
Beyond the basic two-site replication, SRDF supports a range of advanced, multi-site topologies to meet complex business continuity requirements. The E20-807 Exam will expect you to be familiar with these configurations. One of the most common is SRDF/STAR. This is a three-site topology that typically combines the benefits of both synchronous and asynchronous replication. An application at the primary site might replicate synchronously to a nearby secondary site (for zero data loss) and concurrently replicate asynchronously to a third, distant site for protection against a regional disaster.
In a typical SRDF/STAR configuration, the primary site (A) replicates to a synchronous target (B) and an asynchronous target (C). The site B also replicates asynchronously to site C. This creates a redundant path, so that if site A fails, site B can take over production and continue replicating to site C. This provides robust protection against both local and regional outages. Understanding how to manage the data paths and failover scenarios in a STAR environment is an expert-level skill tested on the E20-807 Exam.
Another incredibly powerful advanced topology is SRDF/Metro. This solution provides active-active access to data at two different sites, typically in a metropolitan area. With SRDF/Metro, the storage LUNs at both sites are read/write accessible to hosts at both locations simultaneously. The underlying SRDF synchronous replication ensures that the two copies of the data are always identical. This enables non-disruptive data mobility and continuous availability. If one site fails, applications can continue running at the surviving site without any interruption or need for a failover operation.
SRDF/Metro relies on a host-level clustering solution (like VMware HA or Oracle RAC) and a witness or quorum mechanism to manage potential split-brain scenarios. The VMAX array presents the LUNs as a single, consistent device across both sites. The E20-807 Exam will require you to understand the architecture of SRDF/Metro, its use cases, the role of the witness, and how it differs from traditional disaster recovery solutions. It represents the pinnacle of availability and is a key technology for any VMAX expert to master.
Effective management of an SRDF environment is a critical skill for any professional responsible for business continuity. The E20-807 Exam will test your practical knowledge of day-to-day SRDF operations. A fundamental task is monitoring the health and status of the SRDF links and device pairs. This can be done through Unisphere's replication dashboard or using CLI commands like symrdf query. You need to be able to quickly identify the state of the pairs (e.g., Synchronized, Consistent, Split) and check for any network or performance issues.
Performing a disaster recovery test is a common and essential procedure. This typically involves using the symrdf split command to gracefully suspend replication, allowing the R2 devices to be brought online at the secondary site for testing. This allows the business to validate its recovery procedures without impacting the production application at the R1 site. After testing is complete, the pairs can be re-established and synchronized. The E20-807 Exam may present a scenario that requires you to outline the steps for a non-disruptive DR test.
In the event of an actual disaster, you must know the correct procedure to failover operations to the R2 site. This is a critical sequence of events that involves stopping replication, making the R2 devices read/write enabled, and coordinating with server and network teams to bring the applications online. The symrdf failover command is designed to assist with this process. Equally important is the failback procedure, which is the process of returning production to the original R1 site after it has been repaired.
Finally, you must be familiar with consistency technology. For large applications that span many LUNs, it is vital that all data is replicated in a consistent state. SRDF uses consistency groups to manage this. All devices within a consistency group are treated as a single entity. When replication is managed for the group, SRDF ensures that all writes are applied at the R2 site in the same order they occurred at the R1, preserving the integrity of dependent-write applications like databases. The E20-807 Exam will expect you to understand the importance and application of consistency groups.
Go to testing centre with ease on our mind when you use EMC E20-807 vce exam dumps, practice test questions and answers. EMC E20-807 VMAX3 Solutions Expert Exam certification practice test questions and answers, study guide, exam dumps and video training course in vce format to help you study with ease. Prepare with confidence and study using EMC E20-807 exam dumps & practice test questions and answers vce from ExamCollection.
Purchase Individually
Site Search:

SPECIAL OFFER: GET 10% OFF

Pass your Exam with ExamCollection's PREMIUM files!
SPECIAL OFFER: GET 10% OFF
Use Discount Code:
MIN10OFF
A confirmation link was sent to your e-mail.
Please check your mailbox for a message from support@examcollection.com and follow the directions.

Download Free Demo of VCE Exam Simulator
Experience Avanset VCE Exam Simulator for yourself.
Simply submit your e-mail address below to get started with our interactive software demo of your free trial.
hope to look at E20-807 dumps, thank you very much.
Please , I want to know the date expiration for this exam or Until that date is valid
Best Regards